
写文章




- @weixin_43720054
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
PaddleOCR训练自己的数据集
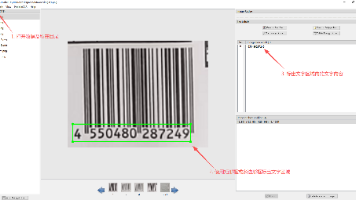
本文介绍了基于PaddleOCR-2.7框架的OCR模型训练流程,主要包括环境配置、数据标注、文本检测和识别训练四个部分。首先配置了CUDA 11.6环境并安装PaddlePaddle和相关依赖。其次使用PPOCRLabel工具进行数据标注,生成训练所需的Label.txt和rec_gt.txt文件。然后详细说明了文本检测模型的训练过程,包括配置文件修改、训练执行、模型验证和导出。最后介绍了文本识
SlowFast训练自己的数据集
SlowFast训练自己的数据集
[SlowFast代码复现] 并用自己的视频进行检测
Linux下SlowFast环境安装与运行
到底了