




- @weixin_43693967
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
git clone 指定的tag。已有仓库切换 tag。

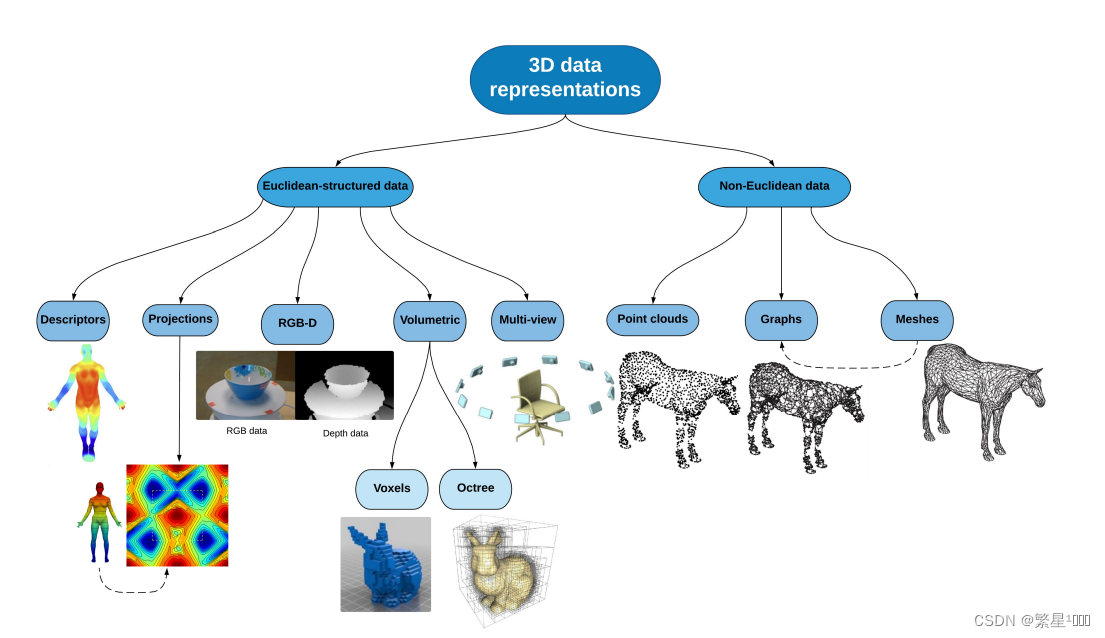
介绍主流3D数据类型
1. sh命令2. expect命令2.1 安装expectsudo apt-get install expect3. 实战3.1 expect+sh实现批量自动创建用户#!/bin/bash#!/user/bin/expectpasswd=Fight666list="username1 username2"addgroup groupname1for i in $list;doexpect &l
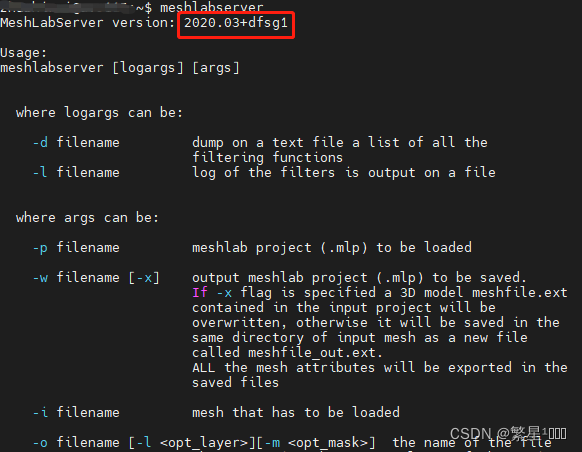
直接用命令装就行,我服了,我还去meshlab官网下载安装包,最新的linux版本还是啥appImage,flatpakref这种安装形式,最重要的是没有meshlabserver,从2020.12版本开始就不提供meshlabserver了。我又去找以前的版本,害,2020.09版本,确实有meshlabserver。还得自己添加环境变量。meshlabserver运行截图,原来装的是2020.
自编码器本质就是将高维数据投影成低维特征,编码器网络拟合着投影函数,解码器网络拟合着反投影函数。神经网络本质就是一个拟合函数。
自编码器本质就是将高维数据投影成低维特征,编码器网络拟合着投影函数,解码器网络拟合着反投影函数。神经网络本质就是一个拟合函数。
自编码器本质就是将高维数据投影成低维特征,编码器网络拟合着投影函数,解码器网络拟合着反投影函数。神经网络本质就是一个拟合函数。
【pytorch】tensor的维度索引,a[:,:,1]与a[:,1]的区别。
直接用命令装就行,我服了,我还去meshlab官网下载安装包,最新的linux版本还是啥appImage,flatpakref这种安装形式,最重要的是没有meshlabserver,从2020.12版本开始就不提供meshlabserver了。我又去找以前的版本,害,2020.09版本,确实有meshlabserver。还得自己添加环境变量。meshlabserver运行截图,原来装的是2020.