




- @weixin_43480227
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Ollama与vLLM性能对比及选型建议 测试数据显示: 低并发场景(1-5并发):Ollama响应更快(中位数6300-8600ms),vLLM吞吐量略高。 高并发场景(10-20并发):vLLM性能优势显著(中位数9400-9900ms),吞吐量及稳定性均优于Ollama(Ollama中位数达16000ms)。 推荐场景: 个人电脑/低负载:Ollama(响应延迟低) 服务器/高并发:vLLM
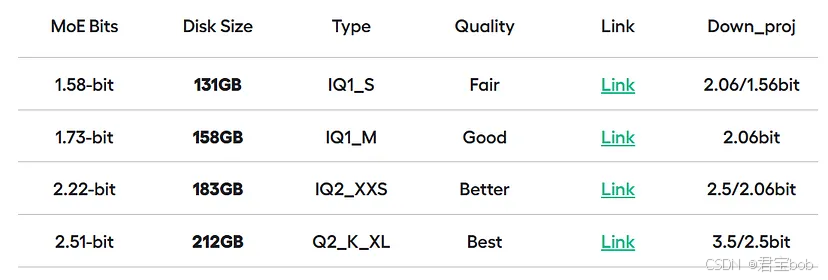
或者 8卡 80G显存的H800. 可以考虑2.51-bit量化版本预测速度预估20~30TPS(待验证)或者 8卡 40G显存的A6000. 可以考虑2.51-bit量化版本预测速度预估3~10TPS (待验证)基于8卡 24G 显存的4090全可以考虑1.58-bit版本,预测速度预估3~10TPS(待验证)基于4/ 8卡96G 显存H20 ,预测速度22tps8张卡每张卡显存占用30。跟进D
本文介绍了如何使用Ollama在CPU环境下快速部署QWen2.5VL-3B模型的方法。通过简单的snap安装命令即可完成部署,支持在普通笔记本电脑上运行,无需GPU或Docker。文中提供了从安装、拉取模型到API调用的完整流程,并展示了WebUI交互界面。同时还预告了GPU版本的部署方案,支持多种显卡型号。部署过程简单快捷,适合开发者快速搭建本地AI对话系统。
亲自验证:以下方案可行。记录并分享。

python的dask搭建分布式集群一、dask介绍dask官网地址:https://dask.org/优势:dask内部自动实现了分布式调度、无需用户自行编写复杂的调度逻辑和程序;通过调用简单的方法就可以进行分布式计算、并支持部分模型的并行化处理;内部实现的分布式算法:xgboost、LR、sklearn的部分方法等用一句话说:dask就是python版本的spark,是一个用Python 语言
或者 8卡 80G显存的H800. 可以考虑2.51-bit量化版本预测速度预估20~30TPS(待验证)或者 8卡 40G显存的A6000. 可以考虑2.51-bit量化版本预测速度预估3~10TPS (待验证)基于8卡 24G 显存的4090全可以考虑1.58-bit版本,预测速度预估3~10TPS(待验证)基于4/ 8卡96G 显存H20 ,预测速度22tps8张卡每张卡显存占用30。跟进D
或者 8卡 80G显存的H800. 可以考虑2.51-bit量化版本预测速度预估20~30TPS(待验证)或者 8卡 40G显存的A6000. 可以考虑2.51-bit量化版本预测速度预估3~10TPS (待验证)基于8卡 24G 显存的4090全可以考虑1.58-bit版本,预测速度预估3~10TPS(待验证)基于4/ 8卡96G 显存H20 ,预测速度22tps8张卡每张卡显存占用30。跟进D
m 06:59:32 ethminer 6:14 A95 30.99 Mh - cu0 12.18, cu1 18.82i 06:59:33 ethminer Job: 4eba272a… eth.f2pool.com [47.108.194.7:6688]i 06:59:33 ethminer Job: 1bc542be… eth.f2pool.com [47.108.194.7:6688]i
亲自验证:以下方案可行。记录并分享。
②开发效率上由于ThingJS形成了一系列的封装,有很多快捷代码和高级封装,不像传统的3D可视化开发要从底层开始写,只要接触过JS语言或是前端引擎的,就能去构建一个3D可视化应用,大大降低开发效率;