- @weixin_43414521
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
>- **🍨 本文为[🔗365天深度学习训练营]中的学习记录博客**>- **🍖 原作者:[K同学啊]**🏡 我的环境:论文地址:Conditional Image Synthesis with Auxiliary Classifier GANsACGAN的全称是 Auxiliary Classifier Generative Adversarial Network ,翻译成汉语的意思就是

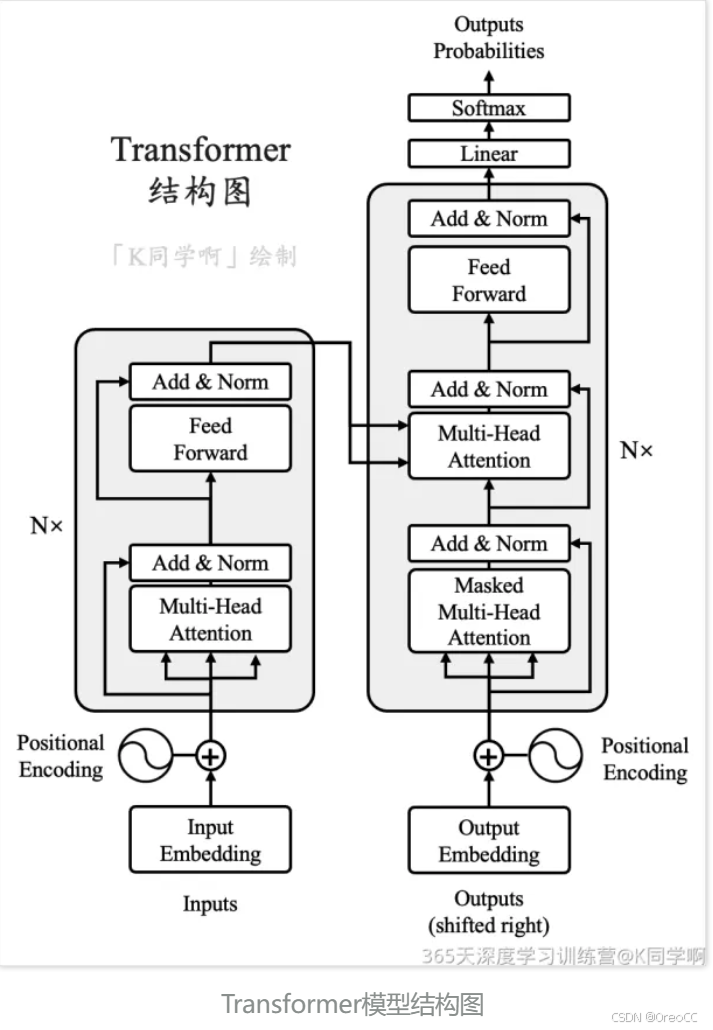
📌本周任务详情:在之前的任务重我们学习了 Seq2Seq,知晓了 Attention 为 RNN 带来的优点。那么有没有一种神经网络结构直接基于 attention 构造,并且不再依赖 RNN、LSTM 或者 CNN 网络结构了呢?答案便是:Transformer。Seq2Seq 和 Transformer 都是用于处理序列数据的深度学习模型,但它们是两种不同的架构。1.Seq2Seq:2.Tr

>- **🍨 本文为[🔗365天深度学习训练营]中的学习记录博客**>- **🍖 原作者:[K同学啊]**🏡 我的环境:本周任务:输出:1. 搭建语言类2. 文本处理函数3. 文件读取函数.startswith(eng_prefixes)是字符串方法 startswith() 的调用。它用于检查一个字符串是否以指定的前缀开始。输出:二、Seq2Seq 模型1. 编码器(Encoder)2.
自然语言处理(NLP)是一种涉及到处理语言文本的计算机技术。在NLP中,最小的处理单位是词语,词语是语言文本的基本组成部分。词语组成句子,句子再组成段落、篇章、文档,因此处理NLP问题的第一步是要对词语进行处理。在进行NLP问题处理时,一个常见的任务是判断一个词的词性,即动词还是名词等等。这可以通过机器学习来实现。具体地,我们可以构建一个映射函数 f(x)->y ,其中 x 是词语, y 是它们的
- **🍨 本文为中的学习记录博客****📌第P2周:彩色图片识别📌。

训练循环size=len(dataloader.dataset) # 训练集的大小num_batches=len(dataloader) # 批次数目,(size/batch_size,向上取整)train_loss,train_acc=0,0 # 初始化训练损失和正确率for x,y in dataloader: # 获取图片及其标签# 计算预测误差pred=model(x) # 网络输出。
model.train() # 切换为训练模式optimizer.zero_grad() # grad属性归零loss=criterion(predicted_label,label) # 计算网络输出和真实值之间的差距,label为真实值loss.backward() # 反向传播torch.nn.utils.clip_grad_norm_(model.parameters(),0.1) # 梯
- **🍨 本文为[]中的学习记录博客**>- **🍖 原作者:[]**● 难度:夯实基础● 语言:Python3、TensorFlow2🍺 要求:1. 使用categorical_crossentropy(多分类的对数损失函数)完成本次选题2. 探究不同损失函数的使用场景与代码实现🍻 拔高(可选):1. 自己搭建VGG-16网络框架2. 调用官方的VGG-16网络框架3. 使用VGG-1

本次项目耗费很长时间在模型调整上,由于初始结果不理想,想到可能是由于卷积核5*5是否过大导致没能捕捉到敏感信息的缘故,将卷积核调整为3*3,但是结果更差,猜测可能是感受野过小不利于特征信息的捕捉,于是又将卷积核重新调整为5*5。同时,优化器修改为Adam。在此过程中,也曾将学习率修改为1e-3,但效果不理想,改回1e-4后结果达到满意状态。

Transformer 网络架构由 Ashish Vaswani 等人在 Attention Is All You Need 一文中提出,并用于机器翻译任务,和以往网络架构有所区别的是,该网络架构中,编码器和解码器没有采用 RNN 或 CNN 等网络架构,而是采用完全依赖注意力机制的架构。网络架构如下所示:Transformer改进了RNN被人诟病的训练慢的特点,利用self-attention可