- @weixin_43199439
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
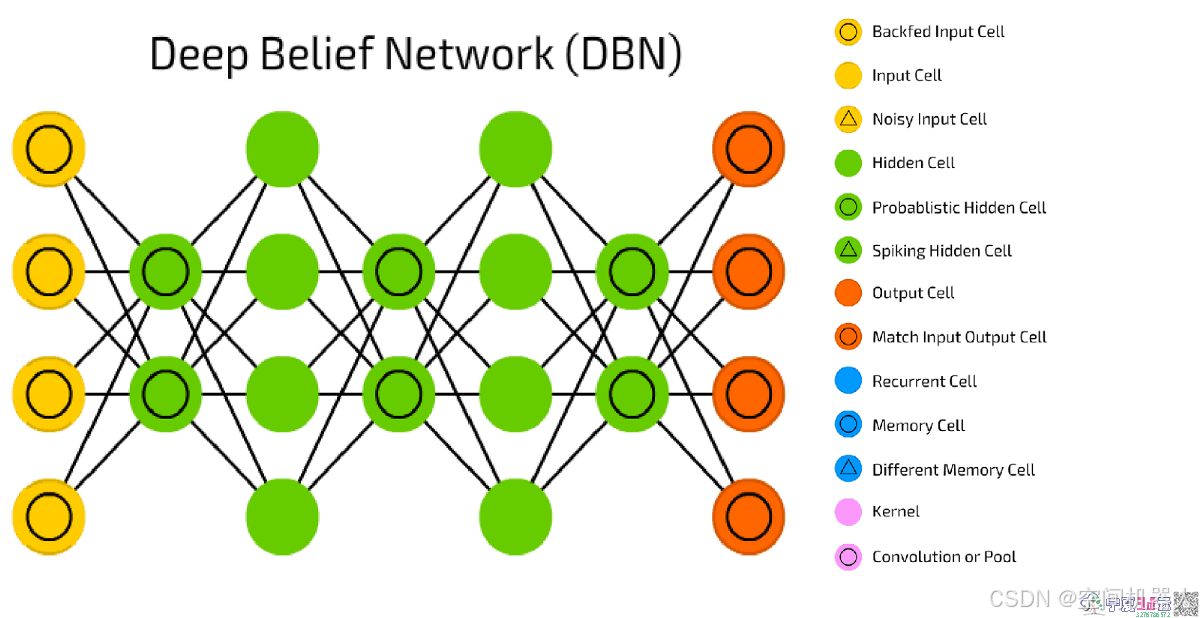
本章详细介绍了完全连接神经网络的基础知识,包括训练循环、损失函数的选择、网络实现和批量训练的优化。随着深度学习的普及,越来越多的工程师和研究人员开始面对如何高效地训练和优化这些模型的问题。虽然当前的技术仍然面临很多瓶颈,但随着研究的深入,我们有理由相信,未来会有更多创新性的技术出现,帮助我们解决这些问题。建议:在实际项目中,设计和训练神经网络时,除了基础的模型架构外,调优训练过程、优化算法和硬件资
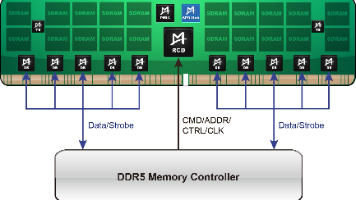
一句特别值钱的话:DDR5 最怕的。从来不是:Training 不过。Training 边缘。因为:能过。不代表:稳。
一句特别值钱的话:DDR5 最怕的。从来不是:Training 不过。Training 边缘。因为:能过。不代表:稳。
如果你在一年前搜索这个话题,可能会看到的是一些晦涩难懂的前沿研究,而如今,大语言模型已经成为科技行业最炙手可热的技术之一。如果你的数据质量不高,那无论模型多强大,最终的效果都会很差。收集数据只是第一步,数据清理才是真正的关键。数据是 LLM 的“燃料”,那么这些数据从哪里来?(Filtering):去掉低质量、错误或有偏见的数据。(Formatting):确保所有数据符合模型输入格式。在讨论技术之

QwQ-32B 是一款专为“复杂推理任务”打造的大型语言模型(LRM, Large Reasoning Model),具备高达320 亿参数的能力。✅比起 DeepSeek-R1 的主模型(6710 亿参数)要小一个数量级;✅远比 o1-mini、Claude Haiku 等轻量模型要强;✅ 同时具备实用性和计算效率,在资源有限场景下依然表现优异。

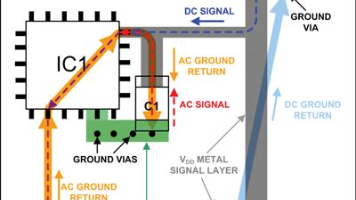
很多工程师第一次做 DDR5。几十 MHz 到几百 MHz。先讲一个很多人没意识到的事。Training 开始不稳。比 DC FAIL 更危险。很多 DDR5 项目。Timing 开始漂。Jitter 开始增。电能不能瞬间跟上变化。举个特别好理解例子。电源允许的最大脾气。
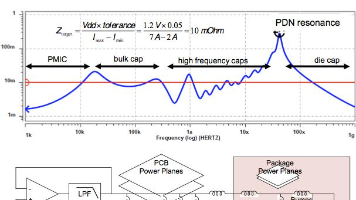
一句特别值钱的话:高频信号。真正难的不是过去。而是:怎么回来。因为:回流路径。EMI稳定性串扰GPSTraining量产风险这篇。你真理解了。高速设计。会突然:开窍。
在Gluon中,损失函数通过loss模块提供。在这个例子中,我们使用的是L2损失(也叫均方误差(MSE)),它衡量的是模型预测值与真实标签之间的差异。L2Loss:计算预测值和真实值之间的平方差并返回该值作为损失。适用于回归任务,尤其是线性回归模型中。优化算法是训练模型的关键部分,负责调整模型参数,使得损失函数的值最小化。小批量随机梯度下降SGD)是最常用的优化方法之一,Gluon提供了Train

这些新推出的AI处理器代表了AMD和英特尔在移动和高性能计算领域的最新技术创新。它们不仅支持传统的计算任务,还能加速AI应用,如机器学习、自然语言处理、图像识别等。随着2025年的上市,预计这些处理器将引领AI PC领域的新潮流,推动AI技术在个人和企业计算中进一步渗透,带来更强的工作效率和创作力。高通宣布推出的。

线性回归虽然是一种简单且高效的模型,但其局限性也是显而易见的,特别是在复杂的实际问题中。通过引入非线性特征转换、鲁棒回归、正则化和降维等技术,可以在一定程度上克服这些瓶颈,提升模型的性能。然而,随着数据和任务的复杂性增加,传统线性回归方法的局限性越来越显著,因此,我们需要通过更强大的模型(如深度学习)来应对更复杂的挑战。在未来的研究和应用中,结合线性回归与深度学习、强化学习等技术,能够为处理大规模