- @weixin_43163941
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
GMR 是一个通用的运动重定向框架,专注于将人类运动数据高精度、实时地重定向到多款人形机器人,同时适配 RL 跟踪策略优化,支持多类人类运动格式和人形机器人型号。,无需从零开发 IK / 关节映射,仅需调用脚本即可完成从各类人体运动数据到多款机器人的重定向,同时适配 RL 训练和实时遥操作场景。这类脚本的核心逻辑是「解析源运动数据 → 调用 GMR 核心算法 → 输出机器人可执行的关节数据」,支持
奖励模型:通过为文本序列的最后一个标记分配标量奖励值,评估生成文本的质量。配对比较数据集:使用首选样本和非首选样本的配对比较数据集,训练奖励模型。损失函数:通过最小化损失函数,模型可以学习到如何区分高质量和低质量的生成文本。b.2)模仿学习:通过使用输入和期望输出的配对数据,模型可以学习从输入到输出的映射。损失函数:结合了奖励模型损失和自回归语言模型损失,通过最小化损失函数,模型可以同时提高区分能

基于云边端协同的系统;特点:IR-L4代表智能机器人的巅峰,系统在感知、决策和执行方面具有完全的自主性,能够在任何环境中独立运行,无需人类干预。特点:引入了初步的环境意识和自主能力,能够在动态环境中执行任务,如服务机器人能够根据语音命令执行不同的任务(如“送水”或“导航引导”),同时在路径执行过程中避开障碍物。特点:具有有限的基于规则的反应能力,能够执行预定义的任务序列,如清洁机器人和接待机器人。
奖励模型:通过为文本序列的最后一个标记分配标量奖励值,评估生成文本的质量。配对比较数据集:使用首选样本和非首选样本的配对比较数据集,训练奖励模型。损失函数:通过最小化损失函数,模型可以学习到如何区分高质量和低质量的生成文本。b.2)模仿学习:通过使用输入和期望输出的配对数据,模型可以学习从输入到输出的映射。损失函数:结合了奖励模型损失和自回归语言模型损失,通过最小化损失函数,模型可以同时提高区分能
1)目标函数使得价值收益最大2)求解梯度上升,但是数据不好去取,3)采用On Policy和Off Policy,用上一轮结果作为当前一轮的输入。
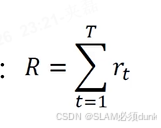
四足机器人在 Isaac Lab 中的完整 RL 训练环境配置,核心目标:柔顺步态控制 + 安全人机交互 + sim2real 虚实迁移,完全匹配你之前的 PACE 系统辨识、柔顺控制研究方向。关键解读ManagerBasedRLEnvCfg:Isaac Lab 标准模块化 RL 环境,把观测、动作、奖励、事件拆分为独立模块,易修改。ROBOT_CFG = UNITREE_GO2_PACE_CFG
1)目标函数使得价值收益最大2)求解梯度上升,但是数据不好去取,3)采用On Policy和Off Policy,用上一轮结果作为当前一轮的输入。
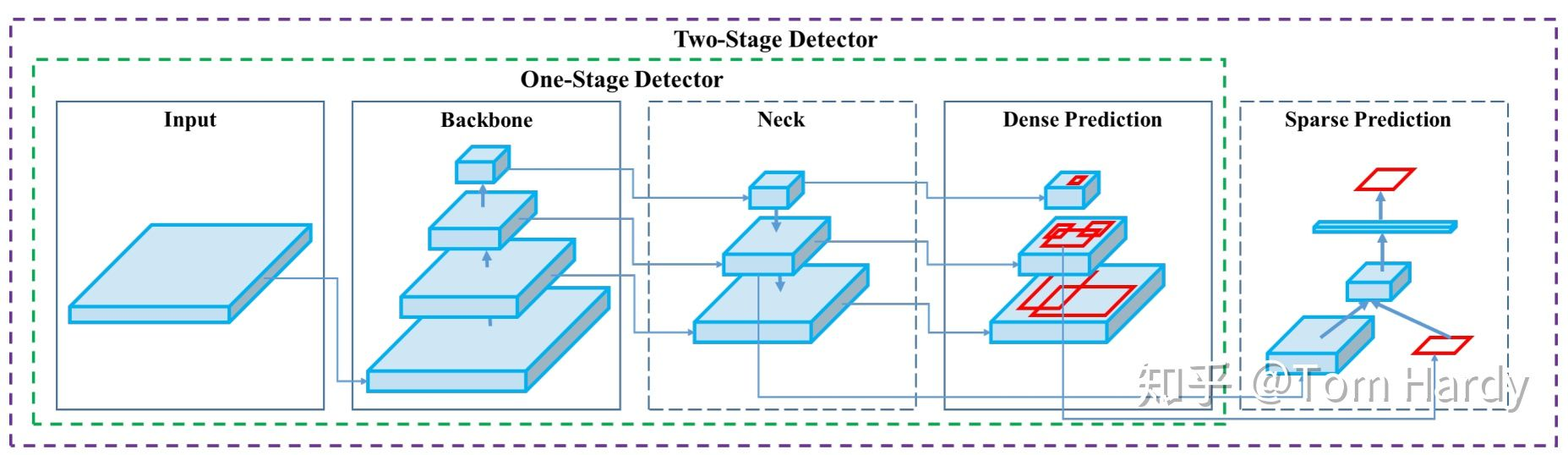
如边缘,纹理,形状等低级特征,以及物体类别,语义等高级特征。ResNet:通过残差连接解决深层网络梯度小时问题,广泛用于图像分类,目标检测等任务,例如在图像分类中,ResNet提取图像的丰富特征,最后通过全连接层输出类别概率。用于预测候选区域边界框的偏移量,调整其位置和大小,使 边界框更精确地匡助目标,输出的是坐标,宽度,高度等维度变化量,不涉及类别判断。,如分类,目标检测,语义分割等,它将nec
基于扩散模型的自车+周车闭环轨迹。从头训练的LLM模型底座。
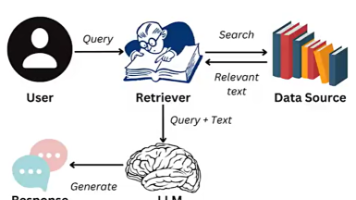
检索增强生成,是一种结合信息检索(Retrieval)和文本生成(Generation)的技术RAG技术通过实时检索相关文档或信息,并将其作为上下文输入到生成模型中,从而提高生成结果的时效性和准确性。