




- @weixin_43064185
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
导语 | 随着业务的发展,系统日益复杂,功能愈发强大,用户数量级不断增多,设备cpu、io、带宽、成本逐渐增加,当发展到某个量级时,这些因素会导致系统变得臃肿不堪,服务质量难以保障,系统稳定性变差,耗费相当的人力成本和服务器资源。这就要求我们:要有勇气和自信重构服务,提供更先进更优秀的系统。文章作者:刘敏,腾讯基础架构研发工程师。前言自今年三月份以来天机阁用户数快速上涨,业务总体接入数达到100
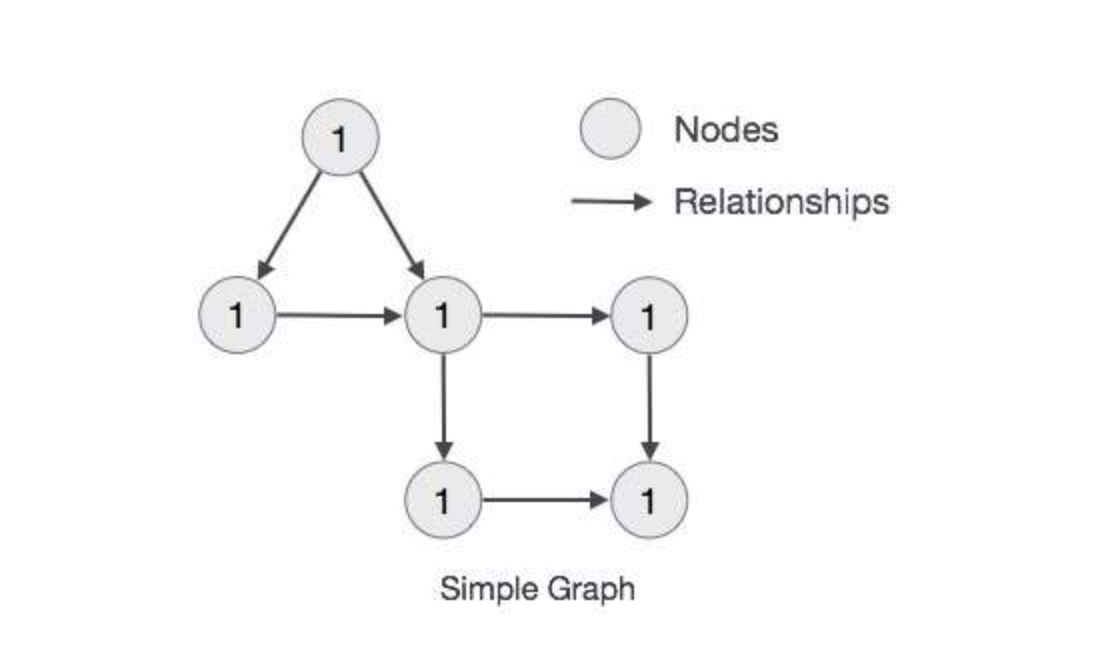
Neo4j是由 Java 实现的开源 NoSQL 图数据库。Neo4j实现了专业数据库级别的图数据模型的存储。与普通的图处理或内存数据库不同,Neo4j 提供了完整的数据库特性,包括 ACID 事务的支持、集群支持、备份与故障转移等,这使其适合于企业级生产环境下各种应用。
安装pip3 install DBUtilsDBUtils是Python的一个用于实现数据库连接池的模块。此连接池有两种连接模式:BDUtils数据库链接池:模式一:基于threaing.local实现为每一个线程创建一个连接,关闭是伪关闭,当前线程可以重复模式二:连接池原理如果有三个线程来数据库中获取连接:如果三个同时来的,一人给一个连接;如果一个一个来,有时间间隔,用一...
环境的准备前端框架semantic uiPython 3.6.4pip install djangopip install django-simple-captchadjango-simple-captcha官方文档地址http://django-simple-captcha.readthedocs.io/en/latest/目标展示配置settings.py...
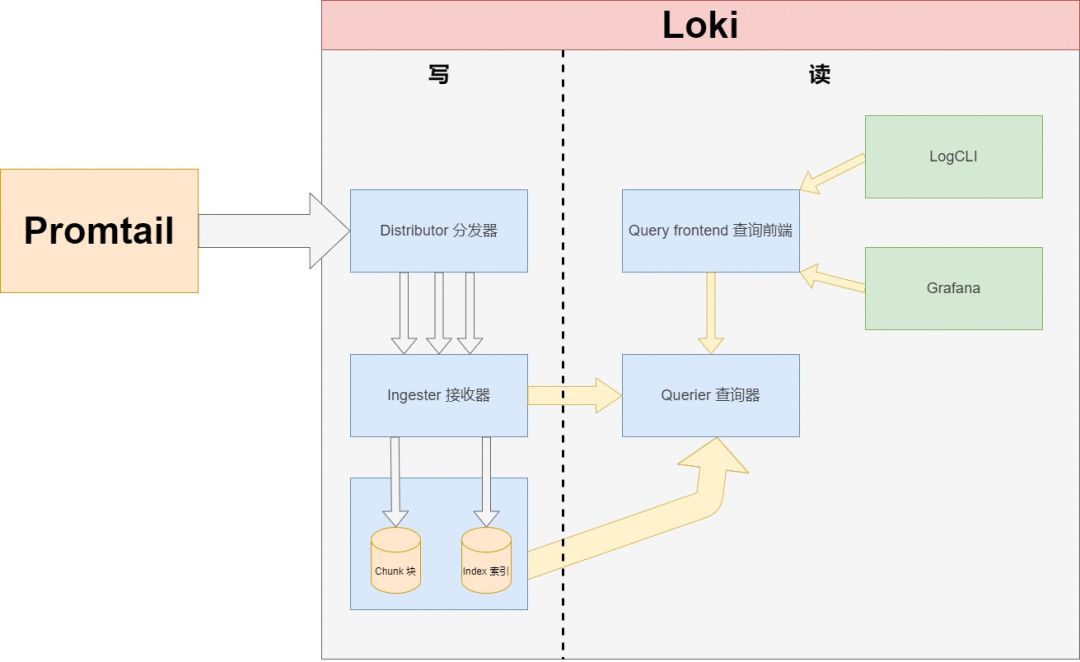
Loki 是受 Prometheus 启发的水平可扩展、高可用、多租户日志聚合系统。非常适合采集 Kubernetes Pod 的日志,关键 Loki 还易于操作且更加轻量级(相比 ELK/EFK/EFLK )。首先,在 Grafana 添加 Prometheus 数据源,URL 只需要填入 http://loki-ip:3100/loki 即可将 LogQL 查询转换为 Prometheus 指
文档:dockerhup-elastucsearch-dumpDocker installdocker pull taskrabbit/elasticsearch-dump官方例子# 使用映射将索引从生产复制到暂存:docker run --rm -ti taskrabbit/elasticsearch-dump \--input=http://produ...
在 Go 1.11 版本之前,Go 语言使用 GOPATH 环境变量来管理项目的依赖。但是从 Go 1.11 版本开始,引入了 Go Modules 的概念,可以更方便地管理项目的依赖关系。当你的项目使用 Go Modules 进行依赖管理时,可以使用r 命令将项目依赖的模块复制到vendor目录下。这样做的好处是,可以将项目所需的依赖模块与项目代码一起打包,使得项目更加独立和可移植。

文档:dockerhup-elastucsearch-dumpDocker installdocker pull taskrabbit/elasticsearch-dump官方例子# 使用映射将索引从生产复制到暂存:docker run --rm -ti taskrabbit/elasticsearch-dump \--input=http://produ...
pandas.Series.str.extract¶Series.str.extract(self,pat,flags = 0,expand = True)[来源]提取的正则表达式捕获组拍作为一个数据帧列。对于系列中的每个主题字符串,从正则表达式pat的第一个匹配中提取组。参数:pat:str具有捕获组的正则表达式模式。flags:i...
关于数据库中行数统计,无论是MySQL还是Oracle,都有一个函数可以使用,那就是COUNT尝尝问道以下问题1、COUNT有几种用法?2、COUNT(字段名)和COUNT(*)的查询结果有什么不同?3、COUNT(1)和COUNT(*)之间有什么不同?4、COUNT(1)和COUNT(*)之间的效率哪个更高?5、为什么《阿里巴巴Java开发手册》建议使用COUNT(*)...