- @weixin_42645636
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
我们提出了一个从粗到细的SfM框架,以从最近无检测器匹配器的成功中获益,同时解决无检测器匹配器的多视图不一致问题。

【摘要】因果机器学习成为AI研究热点,在医疗、商业等领域展现应用价值。本文综述15篇顶会顶刊论文,涵盖单细胞基因组学、电商退货优化、交通影响分析等方向,重点介绍创新方法如cellSCM模型、个性化绿色轻推策略、双重稳健学习框架等,并探讨医学治疗预测的个体化应用。研究强调需突破简单模型套用,关注理论优化与跨领域融合。附开源代码助力复现研究。(149字)
ICML 2024今天开放投稿了!距离截稿还有24天,想冲ICML的同学速度!ICML 全称 International Conference on Machine Learning,由国际机器学习学会(IMLS)举办,与NIPS一同被认为是人工智能、机器学习领域难度最高的国际会议(含金量也超高)。值得一提的是,ICML收录的文章中,中国作为第一作者单位的占比最高,高达51.45%。文末附ICML

朋友们,ICLR 2024这周放榜了!据统计,本届会议共收到了7262篇论文,整体接收率约为31%,与去年(31.8%)基本持平。其中Spotlight论文比例为5%,Oral论文比例为1.2%。不知道各位看完有什么感想,我只觉卷上加卷,仿佛误入神仙打架现场...听说还有热度非常高的论文被拒稿,这下对31%接收率下的神文都讲的啥更好奇了。
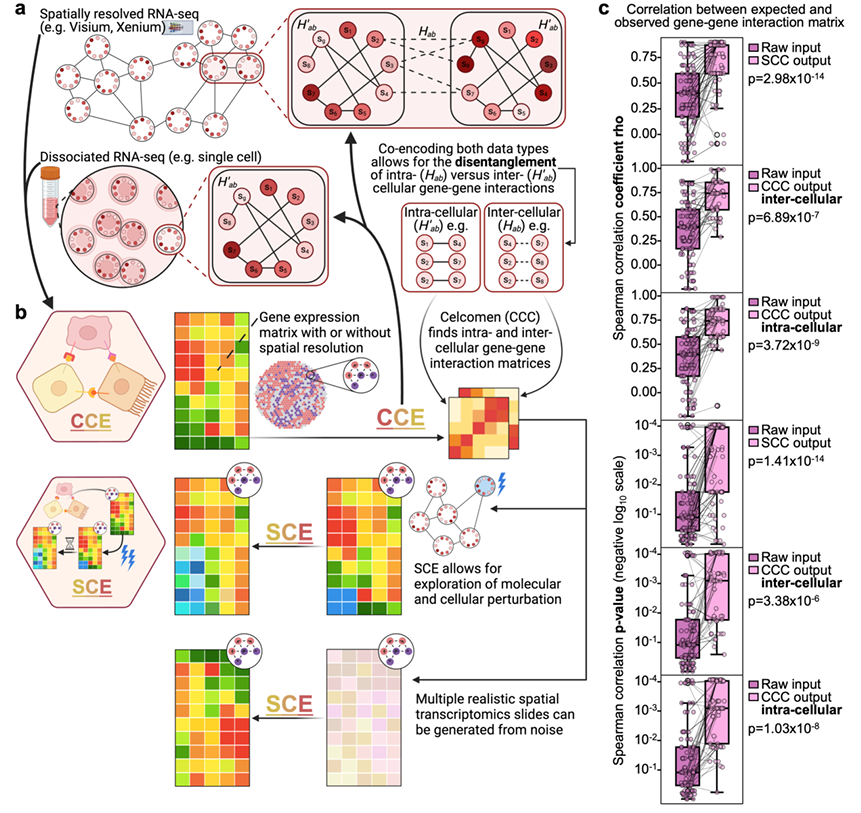
看了这几年各大顶会的投稿趋势,发现相关的论文增长迅猛,研究热情高涨。比如ICLR 2025上剑桥大学提出的Celcomen模型,首次实现空间转录组学因果推断可识别性。不仅如此,机器学习+因果推断在工业界的需求同样旺盛,微软、Uber等企业纷纷入场,医疗、金融、自动驾驶等领域还存在大量未解决的因果建模问题,这些可都是丰富的应用场景和创新切入点。2025年,我们可以从。
他以其幽默和生动的教学风格,让那些复杂难懂的机器学习概念变得易于消化。更赞的是,他的课程全程用中文讲解,为我们中文学习者提供了超大的便利!这套教程覆盖了从机器学习基础、深度学习基本概念,到卷积网络、循环神经网络、扩散模型、Transformer等共计19个章节,内容不仅全面,还特别降低了学习难度。每个公式都附有详细的推导过程,同时提供了丰富的可视化示例。强烈推荐给所有对机器学习感兴趣的朋友们!今天

百度最近又搞了波大的,推出了一种全新的实时端到端目标检测算法RT-DETRv3,性能&耗时完爆YOLOv10。RT-DETRv3基于Transformer设计,属于代表模型DETR的魔改进化版。这类目标检测模型都有着强大的扩展性与通用性,因为Transformer模型的结构可以根据具体任务进行调整和优化,非常适合应对不同的检测需求和场景。更绝的是,Transformer拥有强大的全局上下文建模能力
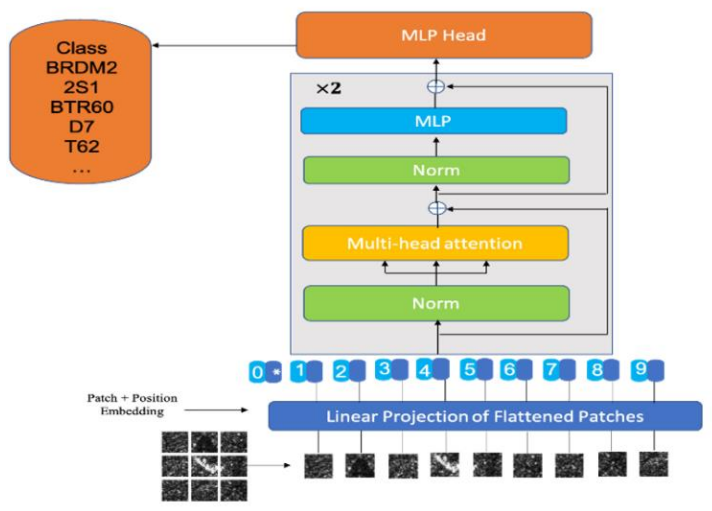
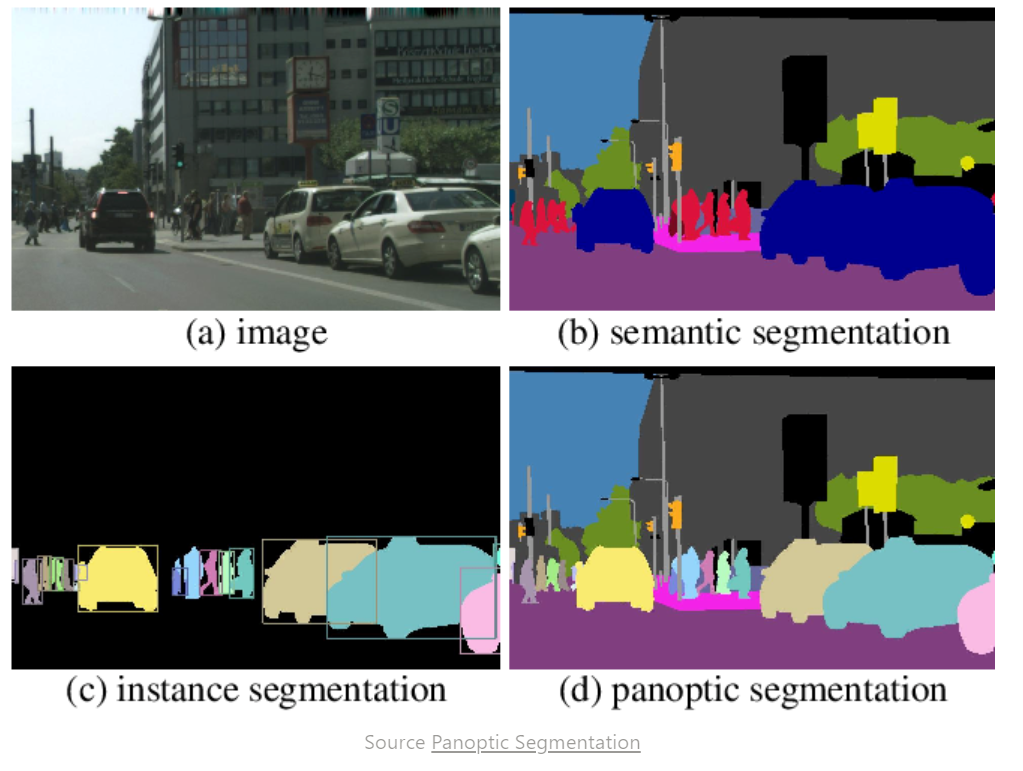
人类对计算机视觉感兴趣的最重要的问题是图像分类 (Image Classification)、目标检测 (Object Detection) 和图像分割 (Image Segmentation),同时它们的难度也是依次递增。在分类任务 (Image Classification) 中,我们只关注图片中物体的类别。目标检测 (Object Detection)任务中,我们不仅要识别出图片中物体的类别
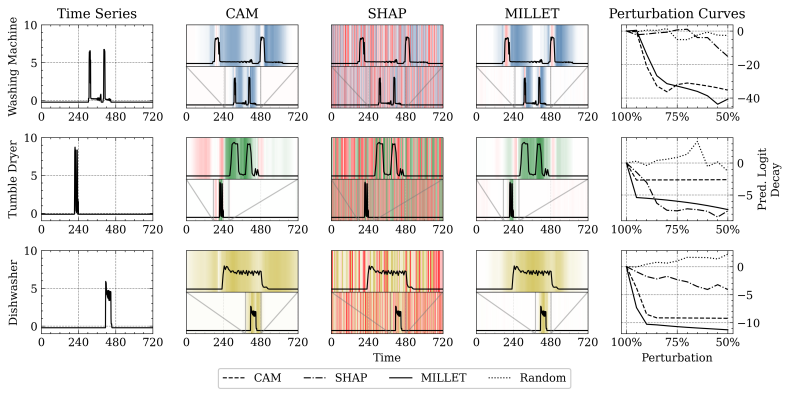
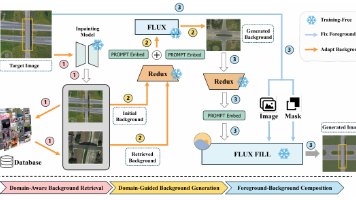
给想要快速发出论文的同学推荐一个“性价比高”的方向——一是因为这方向现实需求迫切,容易讲好“故事”,毕竟在很多领域,收集和标注的成本懂的都懂。二是,FSOD数据需求小,研究门槛低,这意味着实验周期短,非常适合快速迭代想法。而且更重要的是,FSOD与前沿技术结合紧密,创新点多,在CVPR/TPAMI等顶会顶刊上关注度足够,只要工作有亮点,就有机会。那么如何快速发出成果,特别是高区?我的建议是“站在巨
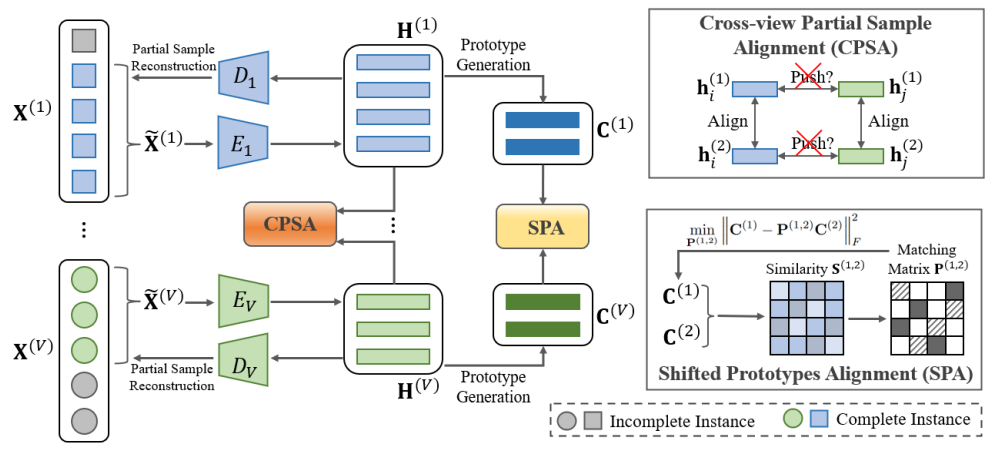
在我们写论文时,深度聚类可以作为数据预处理步骤,帮助我们组织和理解数据集。在论文的实验阶段,深度聚类的结果也可以用作定量和定性分析的一部分。例如,通过展示聚类结果的可视化,我们可以直观地展示自己的方法是如何改善了数据的分离度或发现了有意义的群组。对苦论文久已的我们来说,掌握并进一步探索深度聚类方法显得尤为重要。所以这次我又爆肝汇总了,包括最新的研究成果,还贴上了希望能为同学们的论文主题方法、创新研