




- @weixin_42479421
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本质:的闭环生成范式其他介绍。
会跳过所有 pre-commit / commit-msg 钩子,可能会把不合规的提交推到仓库,应该谨慎使用。,这个路径已在 Windows 命令行的 PATH 中,但 Git Bash 的 PATH 没包含这个目录;(nvm-windows)在 Git Bash 里也不是 bash 的函数/命令,所以会提示。Git 提交被 Husky 的 commit-msg 钩子(配合 commitlint。
(微软自带的,即使未使用,也会拖慢);若还未解决,考虑1GB~32GB、~/.bashrc 文件:git bash打开突然变慢,大约8s,排查原因(之前改过虚存,也设置过git网络的配置,考虑会不会是这个原因),尝试解决无果,我还能忍;vscode改代码连接巨慢,是时候彻底解决了!问题:git bash 启动变慢,连带vscode中使用git变慢。
安全套接字层 (SSL)和传输层安全 (TLS)是用于验证服务器和外部系统(如浏览器)之间数据传输的协议。需要 SSL 证书才能使用 HTTPS保护你的网站。SSL 握手是建立 HTTPS 连接过程的第一步。为了验证和建立连接,用户的浏览器和网站的服务器必须经过一系列检查(握手),这些检查建立了 HTTPS 连接参数。客户端(通常是浏览器)向服务器发送安全连接请求。发送请求后,服务器会向你的计算机
(权限)问题解决:和不要放在同一个文件夹中。1. 新建文件夹 放置 node_global 与 node_cache镜像地址。


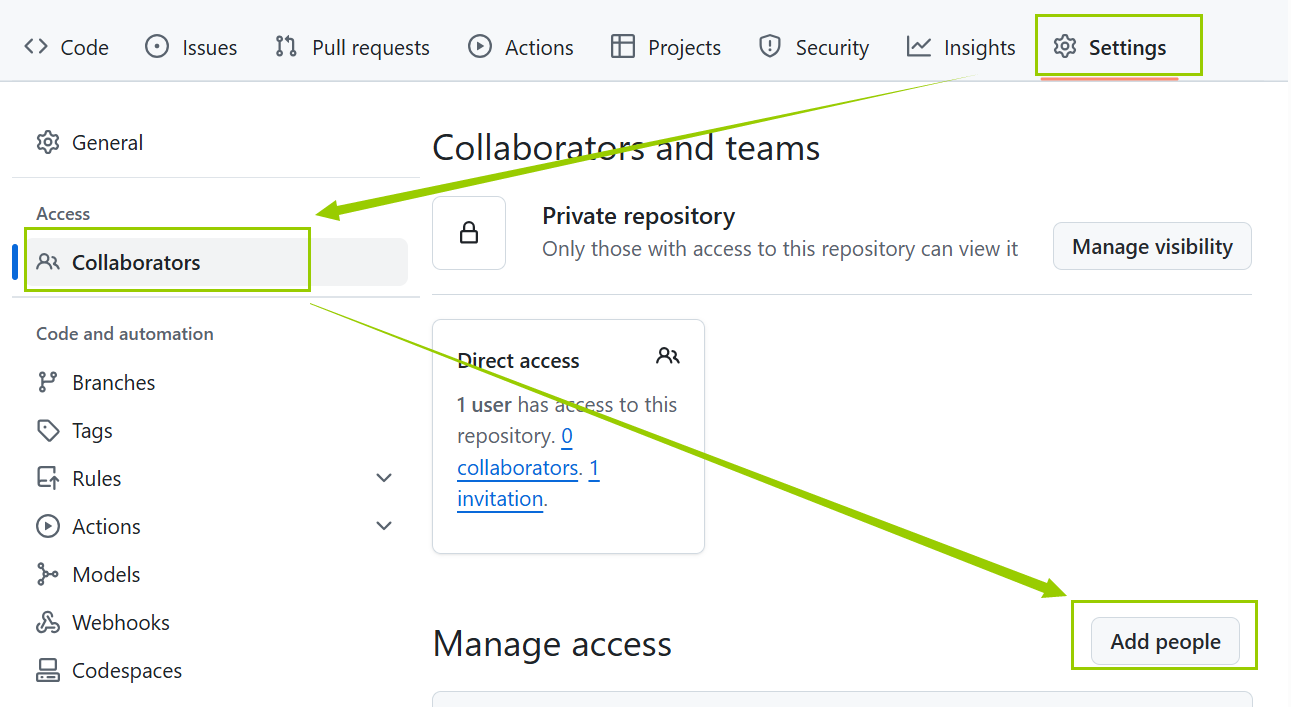
github 给别人开权限仓库 -> Setting -> Cllaborate -> Add peopleGitHub中 将公开仓库改为私有:仓库 -> Setting -> Danger Zone(危险区) ->Change repository visibility( 更改仓库可见性 ) -> Make private( 设为私有 )一、github 给别人开权限省流&总结:仓库 -> Se
VSCode设置位置分为 用户区 和 工作区。用户区,即用户设置,是全局的,对所有工作区和项目都有效。存储在用户配置文件夹中,并以文件的形式保存,与登录的用户账号关联。工作区仅在当前工作区和项目中有效,同时覆盖用户区设置。会创建一个.vscode文件夹,并在其创建settings.json进行配置,来实现特定项目中自定义配置项,而不会影响其他项目。VSCode的设置层级关系系统默认设置(不可修改)

git报错:Failed to connect to github.com port 443 after 21073 ms: Couldn't connect to server
