- @weixin_42380711
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
计算机技术咨询,毕设指导、论文指导
本文针对水下环境复杂、垃圾检测精度低的问题,提出了一种基于YOLOv11的改进算法。通过设计混合结构模块(MixStructureBlock)融合多尺度空洞卷积与混合注意力机制,增强特征提取能力;引入高效多尺度注意力模块(EMA)优化特征图质量。在TrashCan数据集上的实验表明,该算法mAP@0.5达到81.54%和82.75%,显著优于YOLOv11、YOLOv8等基线模型及TC-YOLO等

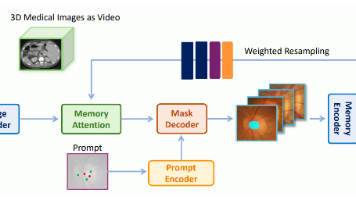
Medical SAM 2 (MedSAM-2) 是基于 SAM 2 的通用医学图像分割框架。它将 2D 和 3D 医学分割任务统一建模为视频目标跟踪问题,核心创新是自排序记忆库——动态选择高置信度特征存入记忆库,实现单提示分割,标注成本降低超 85%。项目开源,支持 REFUGE、BTCV 等数据集。
本文摘要整理了150个计算机领域研究课题,涵盖六大方向: 人工智能与大模型(30项):包括轻量化模型压缩、多模态生成、医疗问答系统、内容溯源等技术; 数据科学与大数据(30项):涉及实时流处理、隐私计算、用户画像、舆情分析等应用; 云计算与分布式系统(25项):聚焦容器化部署、边缘计算、微服务架构等优化方案; 网络安全与区块链(25项):探索智能合约安全、数据溯源、隐私保护等创新应用; 计算机视觉
我们提出了PMData:一个结合了传统的生活记录数据和运动活动数据的数据集。我们的数据集能够开发新的数据分析和机器学习应用程序,例如,额外的运动数据用于预测和分析日常发展,比如一个人的体重和睡眠模式;以及在运动环境中用传统生命数据预测运动员表现的应用程序。PMData结合了来自Fitbit Versa 2智能手表腕带、PMSys运动日志智能手机应用程序和谷歌表单的输入。收集了5个月的记录数据。我们

摘要——遥感图像分割对于地球观测,支撑环境监测和城市规划等应用。由于遥感图像中可用的注释数据有限,许多研究都将数据增强作为缓解深度学习网络过拟合的手段。然而,一些现有的数据增强策略依赖于简单的转换,可能不足以增强数据多样性或模型泛化能力。本文提出了一种新的增强策略 -- 聚块混合马赛克 (clusted-Patch-Mixed Mosaic(CP2M),旨在解决这些限制。CP2M集成了一个马赛克增

2014年牛津大学Visual Geometry Group提出的VGG网络[1],通过系统性探索CNN深度与性能关系,在ImageNet ILSVRC竞赛中取得突破性成果(物体分类第二名,物体检测第一名)。其核心创新在于采用小尺寸卷积核构建深层网络,并通过模块化设计实现参数数量的渐进式增长。
在本笔记本中,我将以我的 Intro to Speech Audio Classification 存储库为基础,并使用 Transformer 编码器网络并行构建两个并行卷积神经网络 (CNN) 来对音频数据进行分类。我们正在研究 RAVDESS 数据集,以对 8 类之一的情绪进行分类。我们将 CNN 用于空间特征表示,将 Transformer 用于时间特征表示。我们通过增加数据集的变化来减少
freeCodeCamp.org是一个非营利性编程学习平台,提供12项免费技术认证课程,涵盖全栈开发、数据科学和机器学习等领域。平台采用自定进度学习模式,包含3000+小时交互式编程练习和50个实战项目,每个认证需约300小时完成。课程特色包括自动化测试、真实项目开发及学术诚信保障,已帮助4万余人进入科技行业。认证内容从基础HTML/CSS到高级Python、机器学习,完成6项核心认证后可申请全栈

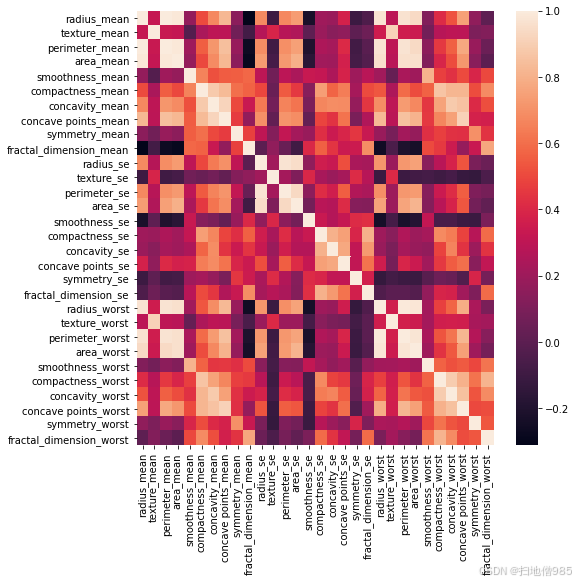
给出的所需元器件库所需的元器件库也列在 Libraries Used (使用的元器件库) 下方。通过创建数据帧并输入准确率分数和相应的机器学习模型,比较了 4 种机器学习模型的预测。测试训练拆分如下: 训练(398 行) : 测试(171 行) :: 70 : 30。创建了一个机器学习模型,通过分析数据集中给出的因素和变量来预测乳腺癌。图 II:这是定义数据集中给定的不同变量/因素之间相关性的热图
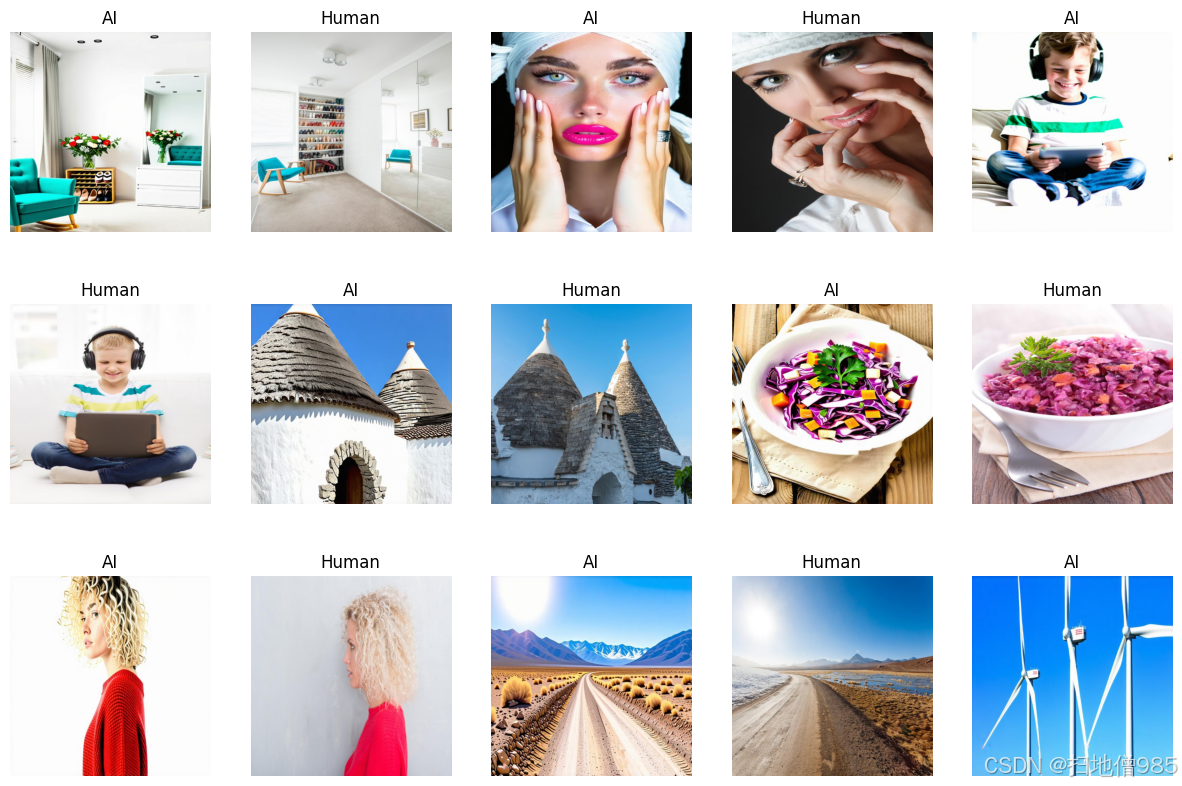
介绍¶区分由人工智能(AI)生成和人类创作的图像至关重要,原因涉及伦理、安全、真实性和社会影响等多个方面。以下是其重要性的具体体现:虚假信息与深度伪造(Deepfakes)AI生成的图像可能被用于传播虚假信息,制造假新闻、宣传或欺骗性内容。深度伪造技术可以冒充真实人物,导致身份欺诈、政治操纵或名誉损害。知识产权与版权问题AI生成的艺术作品引发了关于所有权和版权的问题,尤其是当AI模型基于人类创作的