




- @weixin_42101568
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
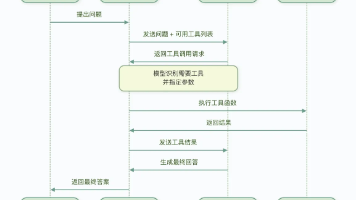
Harness,就是除了模型本身之外,所有的代码、配置、执行逻辑的总和。一个裸的大模型,根本不是 Agent。只有当 Harness 给它赋予了状态管理、工具执行、反馈循环、强制约束这些能力之后,它才变成了一个能干活的 Agent。具体来说,一个完整的 Harness,包含这些核心模块:很多人做 Agent,上来就堆模型,堆工具,结果根本不好用,核心原因就是:你只给了模型一个发动机,却没给它搭一套
手动压缩后,Claude 会给你展示压缩后的摘要,一定要扫一遍:如果发现核心的技术决策、踩坑记录、待办任务有遗漏,立刻发一条消息补充,比如「刚才的压缩摘要里,漏掉了 Redis 的技术选型,麻烦补充到核心技术栈里」,修正后的记忆会更精准。
返回值含义正常完成流式中断工具执行中断超过阻塞限制提示过长达到最大轮数stop hook 阻止hook 停止。

手动压缩后,Claude 会给你展示压缩后的摘要,一定要扫一遍:如果发现核心的技术决策、踩坑记录、待办任务有遗漏,立刻发一条消息补充,比如「刚才的压缩摘要里,漏掉了 Redis 的技术选型,麻烦补充到核心技术栈里」,修正后的记忆会更精准。
在AI应用开发中,让大语言模型(LLM)稳定输出是生产环境的刚需。一旦JSON格式出错,轻则接口解析失败,重则导致整个服务链路崩溃。json {…}想彻底解决,不能只靠 “求模型听话”,必须建立多层防御体系,从软引导到硬约束,层层兜底。
这还只是模型本身的大小,真正的“显存刺客”,是运行时的KV缓存——它的大小完全由上下文长度决定,4K上下文和32K上下文,KV缓存能差出8倍,这也是为什么有人24G能跑,有人40G都炸了的核心原因。绝大多数人玩70B模型,都是用来推理部署,我直接给你实测好的、可落地的显存门槛,同时给你一个可直接复用的显存计算脚本,自己就能精准算。PS:本人部署过70B Deepseek,量化int4,4090显卡

Harness,就是除了模型本身之外,所有的代码、配置、执行逻辑的总和。一个裸的大模型,根本不是 Agent。只有当 Harness 给它赋予了状态管理、工具执行、反馈循环、强制约束这些能力之后,它才变成了一个能干活的 Agent。具体来说,一个完整的 Harness,包含这些核心模块:很多人做 Agent,上来就堆模型,堆工具,结果根本不好用,核心原因就是:你只给了模型一个发动机,却没给它搭一套
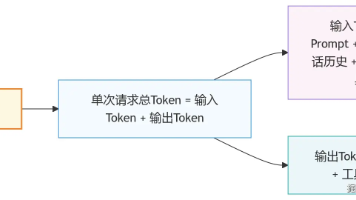
OpenClaw的核心是“Agent调用工具”,而每个工具都有自己的JSON Schema定义——相当于每个工具的“身份证”,每次请求时,都会把当前启用的所有工具的Schema一起发给LLM,让LLM知道“怎么用这个工具”。这部分消耗是“刚性的”,无法压缩,单次请求大概占3000-5000 Token,具体看你启用的工具数量和复杂度。工具Schema 复杂度估算 Token备注browser(浏览
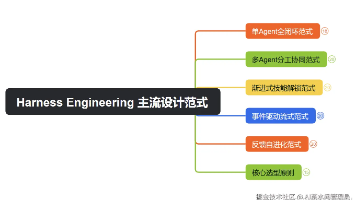
先给大家一个面试能直接说的标准答案,一句话拉开你和 90% 人的差距:Harness 设计范式,是经过生产验证的、可复用的 Harness 架构设计模式,它定义了模型如何与系统交互、任务如何流转、规则如何执行、反馈如何闭环,解决的是「Agent 输出不可控、长任务易失败、场景难扩展」的核心问题。
很多人说,现在大模型越来越聪明,提示词工程很快就会被淘汰。我完全不认同。恰恰相反,未来大模型的能力越强,提示词工程就越重要。因为大模型的能力上限越来越高,能做到的事情越来越多,而能不能把它的能力榨出来,完全取决于你能不能给它清晰、精准、有效的指令。就像同样是一把手术刀,在普通人手里,就是一块废铁;在外科医生手里,就能救死扶伤。提示词工程,就是你用好 AI 这把 “手术刀” 的核心技能。未来,人和人
