




- @weixin_42072959
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
大模型后训练需要用到人类反馈强化学习RLHF,该方法使用PPO算法结合奖励函数实现对LLM的微调,后来出现了DPO算法,即"直接偏好优化"算法,可以直接使用偏好数据对SFT之后的LLM模型进行训练,实现与PPO+Reward同样的效果, 这里的Reward主要指的是结果监督奖励函数,即对LLM输出的整个句子给与一个奖励值,以此引导PPO对LLM的训练优化方向。

AI模型进行边缘计算一般可以进行量化以提高计算效率,PTQ是在模型训练完成后,对模型参数和激活值进行量化的技术。由于无需修改训练过程,其实现简单且开销低。然而,PTQ会在量化过程中引入近似误差,可能导致模型精度下降。QAT通过在训练过程中模拟量化操作,让模型逐步适应量化误差,从而在量化后仍能保持较高精度。其训练过程与标准训练类似,但在每次前向传播中引入了量化和反量化操作。

大模型后训练需要用到人类反馈强化学习RLHF,该方法使用PPO算法结合奖励函数实现对LLM的微调,后来出现了DPO算法,即"直接偏好优化"算法,可以直接使用偏好数据对SFT之后的LLM模型进行训练,实现与PPO+Reward同样的效果, 这里的Reward主要指的是结果监督奖励函数,即对LLM输出的整个句子给与一个奖励值,以此引导PPO对LLM的训练优化方向。
人类:我很羡慕你什么都懂,你的诞生让我感觉自己一无是处Deepseek: 你的羡慕像一扇窗,让我望见了人类最动人的光芒...
使用docker AI镜像可以避免繁琐的AI环境安装配置过程,下面是具体操作流程,还有国内可以的镜像资源以及免费答疑机器人。

使用docker AI镜像可以避免繁琐的AI环境安装配置过程,下面是具体操作流程,还有国内可以的镜像资源以及免费答疑机器人。
本文探讨了国产昇腾AI服务器在支撑大模型训练与推理时的算力需求。随着AI模型规模膨胀,昇腾服务器凭借其高性能硬件成为关键支撑。文中分析了昇腾AI服务器在显存容量与运算速度上的优势,并讨论了如何利用LoRA等技术减轻训练负担。尽管如此,大模型训练仍面临显存占用高的挑战。因此,本文提出采用混合精度训练和分布式训练等策略优化性能,以提升昇腾服务器的算力使用效率,促进国产AI基础设施建设与发展。
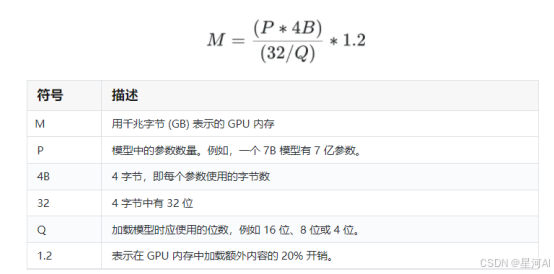
AI模型进行边缘计算一般可以进行量化以提高计算效率,PTQ是在模型训练完成后,对模型参数和激活值进行量化的技术。由于无需修改训练过程,其实现简单且开销低。然而,PTQ会在量化过程中引入近似误差,可能导致模型精度下降。QAT通过在训练过程中模拟量化操作,让模型逐步适应量化误差,从而在量化后仍能保持较高精度。其训练过程与标准训练类似,但在每次前向传播中引入了量化和反量化操作。
大模型后训练需要用到人类反馈强化学习RLHF,该方法使用PPO算法结合奖励函数实现对LLM的微调,后来出现了DPO算法,即"直接偏好优化"算法,可以直接使用偏好数据对SFT之后的LLM模型进行训练,实现与PPO+Reward同样的效果, 这里的Reward主要指的是结果监督奖励函数,即对LLM输出的整个句子给与一个奖励值,以此引导PPO对LLM的训练优化方向。
本文探讨了国产昇腾AI服务器在支撑大模型训练与推理时的算力需求。随着AI模型规模膨胀,昇腾服务器凭借其高性能硬件成为关键支撑。文中分析了昇腾AI服务器在显存容量与运算速度上的优势,并讨论了如何利用LoRA等技术减轻训练负担。尽管如此,大模型训练仍面临显存占用高的挑战。因此,本文提出采用混合精度训练和分布式训练等策略优化性能,以提升昇腾服务器的算力使用效率,促进国产AI基础设施建设与发展。