- @weixin_41072743
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
下载地址:https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/sams/sam_vit_l_0b3195.pth。自动标注工具可以集成SAM实现自动标注的功能。L模型是1.2G 兼顾精度和速度 大概75ms以内。我是直接暴露端口的,然后提供给标注平台使用。主要有三个模型,一般用的B,L比较多一点。


不是因为它背后只有一个更大的模型,而是因为有人认真搭好了提示词、工具、安全、记忆、上下文这些看起来不那么“性感”,却真正决定体验的基础设施。你可以把大模型想象成一匹很强的野马,它冲得很快,也很有爆发力,但问题是它并不天然稳定,也不天然可控。我们平时总在讨论“哪个模型更强”“哪个 agent 更聪明”,但真正把产品体验拉开差距的,往往不只是模型本身,而是模型外面那一整套工程系统。我很喜欢这种设计,因

停车场车位识别是计算机视觉在智能交通领域的典型应用,核心目标是。该项目可解决传统停车场找车位效率低、交通拥堵等问题,为智能停车引导系统提供核心技术支撑。项目整体流程无需依赖预设车位坐标,完全基于原始图像 / 视频实现 “车位区域自动划分 + 占用状态智能判断”,融合了 OpenCV 图像处理、霍夫直线检测、深度学习分类等关键技术,兼具实用性和学习价值。

SIFT(Scale-Invariant Feature Transform,尺度不变特征变换)是计算机视觉领域经典的特征提取算法,由 David Lowe 于 2004 年提出。其核心优势在于具备尺度不变性和旋转不变性—— 无论图像被放大 / 缩小、旋转,都能稳定提取出关键特征点,解决了传统特征提取算法对尺度和旋转敏感的痛点。

全景图像拼接是将多张重叠的局部图像,通过特征匹配、变换对齐和融合拼接,生成一张宽视角、无明显拼接痕迹的完整图像技术。其核心逻辑是找到图像间的重叠特征点,通过数学变换实现图像对齐,最终完成无缝融合。该技术广泛应用于手机全景摄影、无人机航拍测绘、虚拟现实(VR)场景构建等领域,核心依赖特征提取(如 SIFT)、特征匹配、单应性矩阵求解和图像融合四大关键步骤,是计算机视觉中 “图像配准 + 图像融合”

前景是视频中变化的、我们感兴趣的区域;背景是视频中相对静止的、无需重点关注的区域。背景建模的本质的是通过分析像素点在时间维度上的变化规律,判断其属于背景还是前景。接下来,我们将逐一解析两种经典方法的原理与实现。

Harris角点检测算法是一种基于灰度变化的经典特征提取方法。
不是因为它背后只有一个更大的模型,而是因为有人认真搭好了提示词、工具、安全、记忆、上下文这些看起来不那么“性感”,却真正决定体验的基础设施。你可以把大模型想象成一匹很强的野马,它冲得很快,也很有爆发力,但问题是它并不天然稳定,也不天然可控。我们平时总在讨论“哪个模型更强”“哪个 agent 更聪明”,但真正把产品体验拉开差距的,往往不只是模型本身,而是模型外面那一整套工程系统。我很喜欢这种设计,因
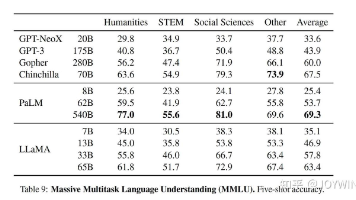
LLaMA是一个系列模型,模型参数量从7B到65B。在大部分的任务上,LLaMA-13B强于GPT-3(175B)。LLaMA-65B的性能,可以和最好的LM相媲美,如Chinchilla-70B 和PaLM-540B。