




- @weixin_40986713
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
MaxKB4j 是一个基于 Java 的开源 RAG 知识库与 LLM 工作流平台,专为企业级智能问答系统设计。核心特性包括:开箱即用的知识库问答,支持多种文档格式上传和网页爬取;模型中立,可灵活对接本地私有模型和国内外主流大模型;提供可视化低代码工作流编排;支持 RESTful API 和前端嵌入组件快速集成。技术栈采用 Java 17 + Spring Boot 3,支持 PostgreSQL

本文探讨了企业级RAG系统技术栈选择问题,通过对比Java和Python在企业应用中的表现,论证了Java在构建高性能、稳定可靠的RAG系统方面的优势。作者基于MaxKB4j开源项目的实践经验,指出Java在性能(JVM vs GIL)、稳定性(强类型系统)、安全性(企业级框架)、可维护性(成熟工具链)以及企业集成能力等方面的显著优势。文章还分析了常见技术选型误区,强调企业级系统应重视长期维护成本

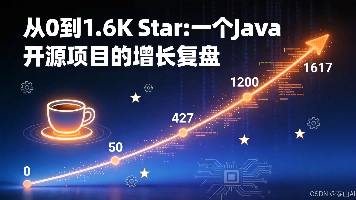
一个人、一年半,MaxKB4j从0做到Gitee 1617 Star / GVP认证的真实复盘,不讲成功学,只讲踩过的坑。
MaxKB4j 是一个基于 Java 的开源 RAG 知识库与 LLM 工作流平台,专为企业级智能问答系统设计。核心特性包括:开箱即用的知识库问答,支持多种文档格式上传和网页爬取;模型中立,可灵活对接本地私有模型和国内外主流大模型;提供可视化低代码工作流编排;支持 RESTful API 和前端嵌入组件快速集成。技术栈采用 Java 17 + Spring Boot 3,支持 PostgreSQL
如果数据库设置密码的话,会提示输入密码注意:用户名后面不要有空格登录成功界面。

前期准备打开电脑画图软件,以window自带的画图软件为例,打开后点击最大化。java代码示例,放在idea里运行即可import java.awt.*;import java.awt.event.*;public class RobotPaint{//中心点x坐标static int centerPx = 360;//中心点y坐标static int centerPy = 540;//起始点x坐
您可以通过下载源代码并编译它自己在任何系统上托管 TimescaleDB。这些说明不需要使用包管理器或安装工具。在开始之前,请确保您已安装:PostgreSQL 12 或更高版本,带有开发环境。有关 PostgreSQL 安装的更多信息,包括下载和说明,请参阅PostgreSQL 文档。CMake 版本 3.11 或更高版本。有关 CMake 安装的更多信息,包括下载和说明,请参阅CMake 文档

MaxKB4J是一款基于Java开发的RAG知识库问答系统,整合了MaxKB和FastGPT的优势,提供开箱即用的智能问答解决方案。系统支持文档上传/自动爬取、文本向量化和检索增强生成,减少大模型幻觉。具备模型中立特性,兼容多种本地及云端大模型,并内置工作流引擎实现复杂业务编排。技术栈采用Java17/SpringBoot3、Vue.js、PostgreSQL等,支持MCP协议实现代码上下文感知。

MaxKB4j 是一个基于 Java/Spring Boot 和 LangChain4j 构建的开源 RAG 知识库与 LLM 工作流平台,支持多模型集成、可视化工作流编排、知识库问答和多模态能力。

数据库设计是指在数据库系统开发过程中,根据用户需求,通过对数据进行分析、抽象和建模,设计出一个合理、高效的数据库结构的过程。在物理设计的过程中,需要对表的存储方式进行规划和设计,以确定表的存储方式和索引。同时,还需要收集和整理用户的需求,并对这些需求进行分类和归纳,以便于后续的数据库设计。因此,在设计数据库时,应该考虑到数据的存储方式、索引、分区和备份等问题,并进行合理的优化和设计。因此,在设计数
