




- @weixin_39074599
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
目前,Kyligence 已支持 DeepSeek 私有化部署方案以及华为云等云平台部署方案,帮助用户快速构建 AI 数据智能体。

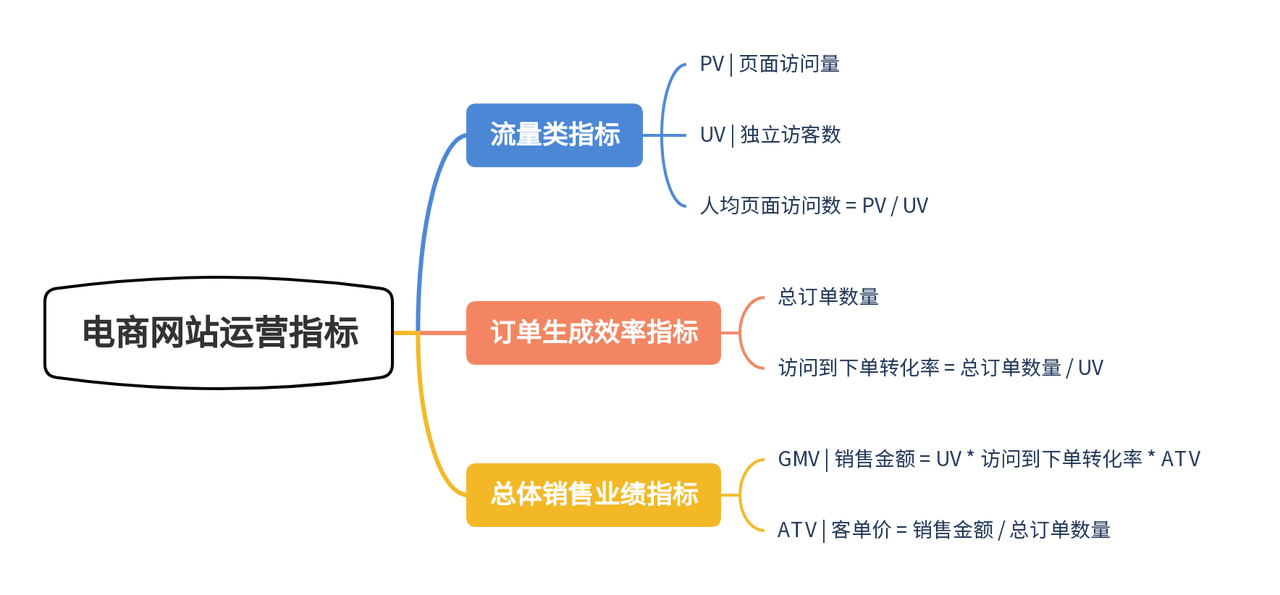
本文介绍电商网站用户运营转化的相关指标体系,通过对这些指标的统计、监测和分析,可以及时发现电商运营的问题,以便有效及时改进和优化,提升电商转化率和销售额。其中,不同类别指标对应电商运营的不同环节,如网站流量指标对应的是网站运营环节;销售转化、销售业绩对应的是电商销售环节。
大家都知道,对于很多架构师而言,做技术选型是一件“常态化工作”。要找准一项技术是否适合某个场景,最核心的是要看这项技术当初是因为什么而诞生的,这个最初始的需求往往就是这项技术的基因。随着技术的持续发展,往往功能会越来越多,枝繁叶茂,但这个基因是我们对这个技术认知的根本。

在本轮评测中,我们从数据计算、数据洞察两个方面对大模型评测结果进行了归类,并提出不同方向的优化建议。如果您正在对大模型进行技术选型,或正在探索大模型在数据分析场景的应用落地与优化方案,欢迎与我们联系沟通。11月21日,Kyligence 将举办。

在训练人工智能时,一般需要经过数据收集、数据清洗、特征提取、模型选择、模型训练、模型测试、部署等一系列步骤。在这一过程中,数据质量的高低对于人工智能的更新迭代极为重要。这也和企业日常数据分析类似,高质量的数据才能更好地支撑用户进行准确的分析和预测,从而帮助企业做出更好的业务决策。

2022年,我国快递业务量完成 1105.8 亿件,业务量连续 9 年位居世界第一,仅用七年时间,中国的快递行业就完成了从百亿到千亿的十倍增长。我国快递物流行业正从蓝海进入红海,在下半场激烈竞争中破局的关键在于客户体验和成本控制,而这两者的改善则离不开数字化和智能化。

在训练人工智能时,一般需要经过数据收集、数据清洗、特征提取、模型选择、模型训练、模型测试、部署等一系列步骤。在这一过程中,数据质量的高低对于人工智能的更新迭代极为重要。这也和企业日常数据分析类似,高质量的数据才能更好地支撑用户进行准确的分析和预测,从而帮助企业做出更好的业务决策。
开年以来,OpenClaw 的爆火让“养龙虾”潮迅速破圈。随着 Agent 能力不断深入业务,Kyligence 接触和服务了越来越多需落地 AI 的行业企业。我们发现,AI 在企业落地的瓶颈往往不在于模型规模,而在于组织运作的精细度与协同效率。步入2026年,AI 的核心竞争已从技术本身转向组织能力——能否高效运作、快速适应,将直接决定落地成效。

开年以来,OpenClaw 的爆火让“养龙虾”潮迅速破圈。随着 Agent 能力不断深入业务,Kyligence 接触和服务了越来越多需落地 AI 的行业企业。我们发现,AI 在企业落地的瓶颈往往不在于模型规模,而在于组织运作的精细度与协同效率。步入2026年,AI 的核心竞争已从技术本身转向组织能力——能否高效运作、快速适应,将直接决定落地成效。
在本轮评测中,我们从数据计算、数据洞察两个方面对大模型评测结果进行了归类,并提出不同方向的优化建议。如果您正在对大模型进行技术选型,或正在探索大模型在数据分析场景的应用落地与优化方案,欢迎与我们联系沟通。11月21日,Kyligence 将举办。