- @weixin_38175458
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
bond_value IC值不明显,分层不单调,但lightGBM的权重重要性很高。咱们还是使用lightGBM集成学习的方式,决策树是可以筛选特征的重要性的。——这是与股票市场不一样的地方,股票退市相对少,而转债本身就有退出周期。有时候,淡定一点,把事情处理得稳妥一点,后续的事情会更少。IC值大,但分层效果不好,大概率因子里包含了非线性因素。结果有可能,事情也许办了,但引入其他更加不可控的事情。

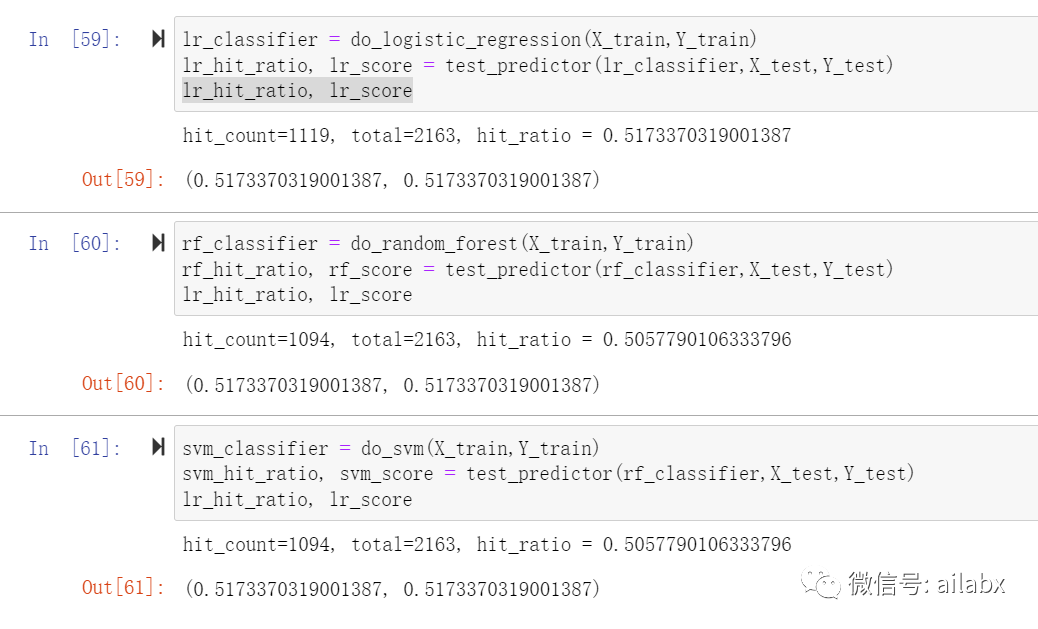
这个过程几乎是标准的,后来主要是添加更多、更好的因子,不同的标注方法,可以是分类也可以是连续的。同时,因子也可以做一些预处理,滤波之类的。金融量化注入到机器学习全流程中,主要就是数据预处理,因子计算,数据自动化标注,然后模型训练,模型预测等等。原创文章第99篇,专注“个人成长与财富自由、世界运作的逻辑, AI量化投资”。实现三个基准模型,分别为logistic回归、随机森森和SVM。第99篇了,第
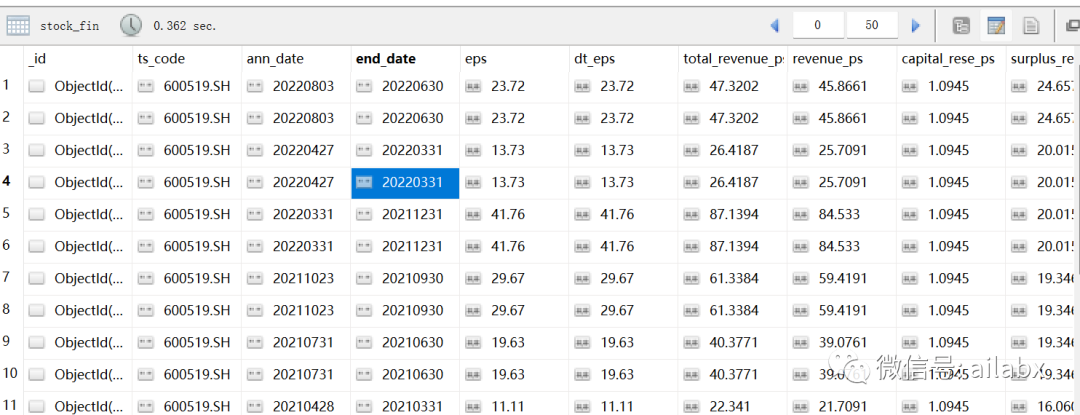
没有什么好的改变会在瞬间发生,都是潜移默化,量化到质变的结果。DumpDataUpdate,其实是追加(日期必须在之后)(已存在的date数据不修改),DumpDataFix就是修改(不存在的date不追加)。假设回到大学毕业,告诉年轻时的自己(不能透露未来信息,比如房价,茅台和腾讯股票之类的未来信息),那站在今天的认知水平上,我们会告诉自己什么呢?到目前为止,我们完成了茅台的时间序列数据,以及财
—这一点上符合逻辑,从机器学习的角度,每天的数据是一个样本,而样本进行minmax,相对大小没有发生改变,只是“归一化”到0-1之间,更符合特定分布。这本书确实写得一般,不同于传统传记,他的写作,更像是要与特斯拉融入一体,那种半梦半醒,活在自我构建的世界,那种感觉。之前聊过比较多“FIRE——财务自由,提前退休”的方式,也聊过“500,10%”的财务自由逻辑。但我们有可能“成为”爱迪生。——实用主
因子挖掘的时候,并不需要传入X,y,我们只为生成符号,而不需要进行计算,计算是在fitness的时候进行,而fitness完成是我们自主定义,我就可以在这个环节对多个symbol进行计算。2、gplearn的符号生成不支持常量,比如roc(close,20),这个20它必须hard code进去,不支持说,你从【1,2,5,10,20,40】里随机选择一下。股票的数据量比较大,还有各种指标,基本面
1、qlib自带的crawler,直接基于网页的采集脚本,一是网络可能不稳定,数据质量无法保证;其实问题反而简单,我们可以不必看那些collector的代码,只知道我们需要把序列写到一个文件目录下的csv即可。qlib的数据库是专门为AI量化定制的,可以多进程并行计算,在海量因子计算的时候有优势。qlib内置的数据源是来自网上,数据质量不高且不稳定,网络不好的时候下载不下来。目前我选用的数据库是t
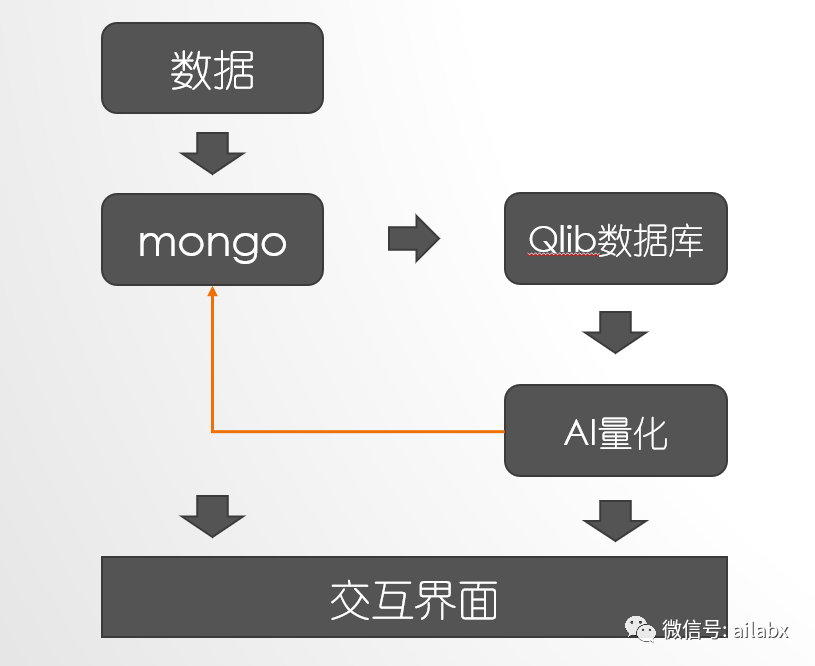
机器模型也是,它是针对每个symbol,训练一个模型,我在想,如果4000支股票,这就训练了4000个模型。由于pybroker是一个symbol一个model,它没有qlib的dataset,可以直接提供数据给机器训练使用,因此,我们借用一下qlib的dataset相关的代码,包括预处理等。而qlib相反,它的传统规则量化非常弱,基本不支持写规则,ai模型出来之后,就一个topK轮动,比如要加一
三年前,开始认真输出内容,就有了B计划的样子。——现在的生活是你三年前、五年前的模式所决定的,没有办法很快去改变。这个需要想清楚,这条路当然优点非常多,尤其适合内向,不喜欢,也不擅长与人协作、打交道的同学们。有时候不是努力就可以的,它需要一种特质,一点点悟性,还有很多的耐心。你理想中的生活与现实中的生活,之间的差距,就是你要去补足的地方。C计划,大胆一点,疯狂一点,守住底线的基础上勇敢做自己。三年
原创内容第923篇,专注智能量化投资、个人成长与财富自由。今天是星球一周一度更新代码的日子,代码已经更新到星球:核心代码所带的策略集,在pycharm下启动终端(默认会激活虚拟环境),然后输入 jupyter notebook:点击“策略集”:点击“机器学习策略”模型训练:因子重要性排序分析:回测:年化25.3%,这是一个完整的机器学习应于量化策略开发的流程。吾日三省吾身《拿铁因素》
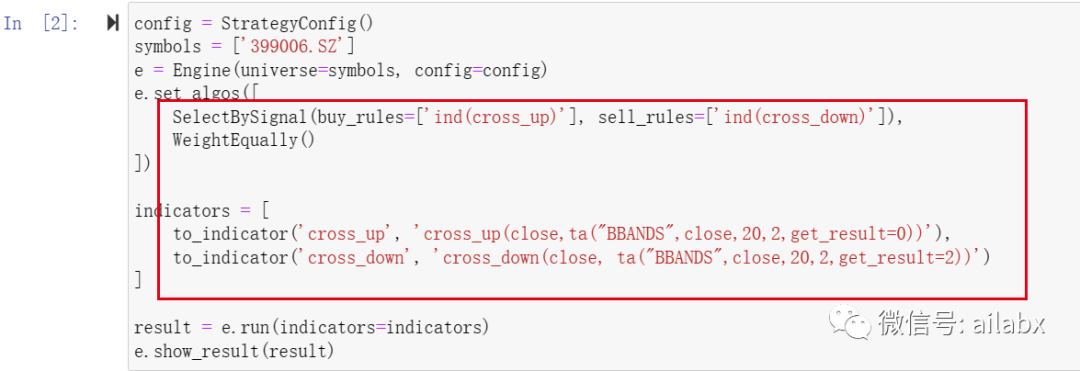
今天开始整合机器学习训练至主界面中。机器学习应用到金融量化的核心框架一个量化策略,无论是传统的技术分析,还是机器学习策略,无外乎几个部分:一、数据准备,一般是整理成pandas的dataframe,包含基础的OHLCV等数据。二、计算衍生指标,比如技术指标、或者worldquant101这样的alpha因子,一切皆因子,即机器学习模型里的特征,机器学习模型还需要打label,即预测未来某段时间的收