- @weixin_37865166
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Qwen3-TTS是团队开发的开源语音合成模型系列,支持多音色、多语种与多方言的语音生成懒人包界面注意,建议显存8GB以上下载并解压懒人包,点击一键启动WebUi.bat等待终端执行执行成功后会自动打开网页网页为https,因为证书问题,需要点击高级,运行,才能正常访问界面本文只演示声音设计比如声音描述为甜美的萝莉音或者可爱的小孩音,都行,声音会按描述的内容生成生成后可以点击试听或者下载目前语音克
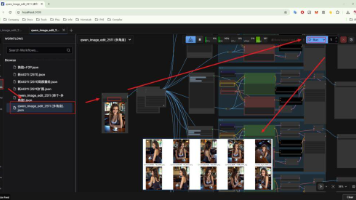
Qwen-Image-Edit-2511 是阿里通义千问团队推出的一个开源图像编辑模型,属于 Qwen-Image 系列中的“编辑(Image Editing)”版本。它的核心定位非常明确:专注于基于文本指令修改图片。简单理解:它 = “比 Stable Diffusion 更擅长改图、而不是单纯生成图”的模型。Qwen-Image-Edit-2511 = 当前开源里“最强调一致性和可控编辑”的图
从之前的fastapi转gradio界面,已经重新打包了3个左右的懒人包核心是为了把编程api转为可视化操作交互网页,更加方便,同时也是为了重新优化项目结构,方便后续更改和优化,比如添加python依赖和添加其他界面功能如果不重新制作懒人包结构,那么后面要做改动,会花费10倍的时间也达不到一个预期的效果,重新制作后,可能几分钟半小时就能大改版现在fastapi的界面几乎没了,开始第二阶段,就是把之
本文依旧是懒人包的优化更新之前最大的问题就是使用fastapi这种偏向编程交互的操作方式适合api调用,不太适合gui界面可视化操作,现在统一把fastapi改为gradio可视化交互关于懒人包,目前最多的系列是ocr,其中pdf转md也最为常用。
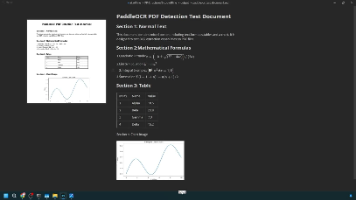
Qwen3-ASR提供0.6B和1.7B两个语音识别模型版本。0.6B版本主打高效低延迟,适合边缘设备和实时场景,具有极快推理速度(~92ms首字响应)和低显存需求。1.7B版本则在准确率上达到SOTA水平,尤其在噪声环境、方言和长语音处理方面表现优异,但需要更强算力支持。两者均支持52种语言识别,开发者可根据业务需求选择:效率优先选0.6B,精度优先选1.7B。使用懒人包可快速体验,但需注意30
本期依旧是把fastapi的界面改为gradio界面原来的fastapi适合api调用,现在的gradio适合界面交互操作本期的更新为只保留PDF转MD和图片转MD的功能,其他如json,html,excel都去掉了只保留GPU版本,无CPU版本,因为VL1.5比较占显存,CPU耗时太长下图是两个版本对比。
Faster-Whisper是Whisper语音识别的高性能工业级推理引擎,通过CTranslate2框架优化,在保持精度的同时显著提升速度(最高4倍)并降低资源消耗。它支持CPU/GPU运行、INT8量化、批量处理,兼容所有标准Whisper模型,输出格式与原版一致。相比官方Whisper和其他实现方案,Faster-Whisper在速度、资源占用和部署便利性上表现更优,适合生产环境使用。不过当
原文地址:https://dsx2016.com/?p=375➢react-native重新编译以下一些情况:新建项目后,第一次运行修改android包名/签名密钥等重要参数后下载第三方模块react-native link原生后莫名其妙的红屏警告功能失效,无法定位错误但是没有明显异常的时候➢gradlew clean...
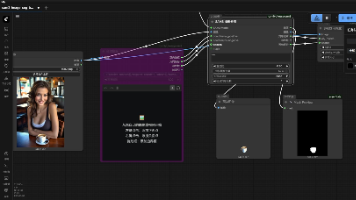
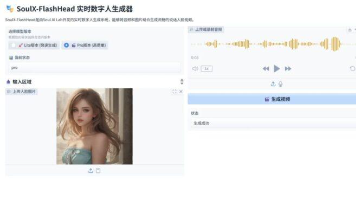
Model_Pro Released可以在单个 RTX4090 上生成 10.8 FPS 的高质量视频,或者在两个。这是一个有soul推出的开源的图片数字人AI,可以实时图片数字人,低显存也可以流畅使用,比如8GB。模型选择lite最快,但是效果较差,选择pro较慢,效果只是相对可以,但是还是不太真实。目前我只测试了它的数字人视频生成,没有测试它的实时效果,暂时用不到实时的功能。然后下载网盘的一键
Meta AI 开源的SAM 3(Segment Anything Model 3)是一个用于图像与视频分割的最新视觉基础模型,来自 facebookresearch 团队。该模型在前代 SAM / SAM 2 的基础上做了较大升级。