




- @wangjye99
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
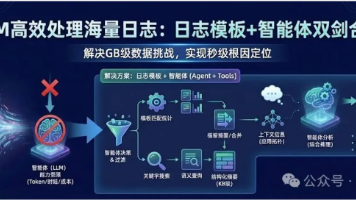
摘要:针对LLM处理海量日志的挑战,提出"日志模板+智能体"方案。通过模板匹配将GB级日志压缩为结构化摘要,结合关键字搜索保留关键细节,利用语义查询增强理解。采用Agent+Tools架构实现动态决策分析,支持按需调用工具组合。该方案有效解决日志数据量与LLM处理能力的矛盾,将原始日志从GB级压缩至KB级,使智能体能快速定位根因。典型场景中,智能体通过分析模板统计趋势和异常日志
本文介绍了NL2SQL(自然语言转SQL)在企业数据分析场景中的应用方案。通过Agent+RAG架构,实现了业务人员自然语言查询到可执行SQL的自动转换。文章详细阐述了从数据准备、知识向量化、RAG检索到Agent配置的全流程,重点讲解了如何构建业务知识库、优化检索策略,以及通过智能体编排实现多阶段推理和SQL验证。该方案解决了传统NL2SQL在表名猜测、业务术语理解等方面的痛点,使业务人员能够直

本文全面解析了大模型应用生态:从基础模型、模型运行、模型优化、开发框架、中间件到应用层,为企业AI落地提供了清晰路线图。文章深入浅出地介绍了各层关键技术与工具,包括主流开源闭源模型、运行环境、优化方法、开发框架、AI Agent与向量数据库等中间件,以及低代码应用平台。这是一份帮助企业和个人理解大模型技术栈、选择适合工具、实现AI价值的实用指南。

我于2022年花费2790元购买的华为显示器,在14个月内竟两次发生主板、屏幕等核心部件故障。产品刚过保修期,官方售后维修报价竟高达2492元。这不仅暴露了其产品存在严重质量缺陷,更以不合理的天价维修费剥夺了消费者的公平交易权。我已拒绝其“打折”方案并向12315平台投诉,以此谴责其利用售后牟利的行为。

本文全面解析了大模型应用生态:从基础模型、模型运行、模型优化、开发框架、中间件到应用层,为企业AI落地提供了清晰路线图。文章深入浅出地介绍了各层关键技术与工具,包括主流开源闭源模型、运行环境、优化方法、开发框架、AI Agent与向量数据库等中间件,以及低代码应用平台。这是一份帮助企业和个人理解大模型技术栈、选择适合工具、实现AI价值的实用指南。
本文全面解析了大模型应用生态:从基础模型、模型运行、模型优化、开发框架、中间件到应用层,为企业AI落地提供了清晰路线图。文章深入浅出地介绍了各层关键技术与工具,包括主流开源闭源模型、运行环境、优化方法、开发框架、AI Agent与向量数据库等中间件,以及低代码应用平台。这是一份帮助企业和个人理解大模型技术栈、选择适合工具、实现AI价值的实用指南。
当我们在 Jupyter Notebook 中查看数据时,有时可能会遇到仅显示部分数据的情况,例如使用省略号(...)表示数据字段。这是因为 Jupyter Notebook 会自动将数据字段的长度限制在一定范围内。本文将介绍如何控制在 Jupyter 中数据字段全部进行显示,而不是显示省略号。

本文全面解析了大模型应用生态:从基础模型、模型运行、模型优化、开发框架、中间件到应用层,为企业AI落地提供了清晰路线图。文章深入浅出地介绍了各层关键技术与工具,包括主流开源闭源模型、运行环境、优化方法、开发框架、AI Agent与向量数据库等中间件,以及低代码应用平台。这是一份帮助企业和个人理解大模型技术栈、选择适合工具、实现AI价值的实用指南。
本文全面解析了大模型应用生态:从基础模型、模型运行、模型优化、开发框架、中间件到应用层,为企业AI落地提供了清晰路线图。文章深入浅出地介绍了各层关键技术与工具,包括主流开源闭源模型、运行环境、优化方法、开发框架、AI Agent与向量数据库等中间件,以及低代码应用平台。这是一份帮助企业和个人理解大模型技术栈、选择适合工具、实现AI价值的实用指南。
Markdown 是一种简单易读、易写的标记语言,而且具有高级功能,例如内联图像和链接等。Markdown 可以用于编写文档、博客、Readme 文件等,因为它的格式简单明了,易于编写和阅读。本文介绍了 Markdown 的常用标记和示例,以及如何在 Markdown 中展示图像、进行换行等。
