




- @u014755700
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
hadoop主要解决:海量数据的存储和海量数据的分析计算hadoop发展历史Google是hadoop的思想之源(Google在大数据方面的三篇论文)2006年3月,Map-reduce和Nutch Distributed File System(NDFS)分别被纳入到Hadoop项目,Hadoop正式诞生。

Linux 是一种常用的开源操作系统,它提供了丰富的命令行工具来进行系统管理和日常操作。以下是一些常用的 Linux 命令:1. 文件和目录操作:- ls: 列出目录内容- cd: 切换目录- pwd: 显示当前工作目录- mkdir: 创建目录- rm: 删除文件或目录- cp: 复制文件或目录- mv: 移动文件或目录- find: 在文件系统中查找文件2. 文件内容查看和编辑:- cat:

MybatisUpdateInterceptor](file://E:\SupplyChain\mdgylxt_sourcing\md-gyl-sourcing-start\src\main\java\com\mdgyl\hussar\sourcing\config\MybatisUpdateInterceptor.java#L24-L174) 是一个 MyBatis 拦截器,用于在数据库操作前后
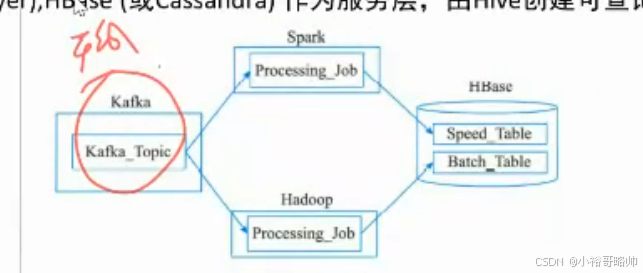
其主要的功能有两方面,一是整合批处理和加速层的数据,数据虽然通过批处理和加速层进入HBase,但是这些数据之间很可能有某些关联关系,在Hbase 存储的时候要保留这些有用的关系,例如车联网的数据虽然有实时数据,但是也有一些实时性要求不高的基础数据是通过批处理层进入,实时数据和基础数据可能要进行合并处理,服务层就可以完成这些需求。项目历时8个月,最终顺利构建了该企业的大数据平台数据湖应用,目前系统运
1.创建当程序使用new关键字创建了一个线程之后,该线程就处于一个新建状态(初始状态),此时它和其他Java对象一样,仅仅由Java虚拟机为其分配了内存,并初始化了其成员变量值。此时的线程对象没有表现出任何线程的动态特征,程序也不会执行线程的线程执行体。2.就绪当线程对象调用了Thread.start()方法之后,该线程处于就绪状态。Java虚拟机会为其创建方法调用栈和程序计数器,处于这个状态的线

2.1 Java NIO 三件套在NIO 中有几个核心对象需要掌握:缓冲区(Buffer)、选择器(Selector)、通道(Channel)。2.1.1 缓冲区Buffer1.Buffer 操作基本API缓冲区实际上是一个容器对象,更直接的说,其实就是一个数组,在NIO 库中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读到缓冲区中的; 在写入数据时,它也是写入到缓冲区中的;任何...