- @u012316485
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
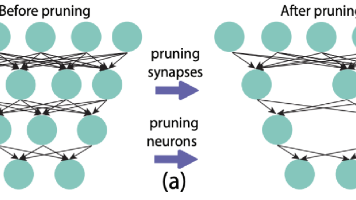
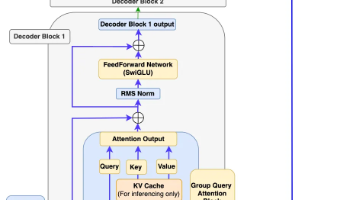
本文详细解析了Llama3架构的实现过程,通过PyTorch从零构建模型。作者首先介绍了Llama3的整体架构特点,包括数据规模扩大、参数规模提升和复杂度管理等关键改进。重点剖析了解码器块的核心组件:RMSNorm归一化、RoPE位置编码、KVCache优化、分组查询注意力(GQA)和SwiGLU前馈网络。
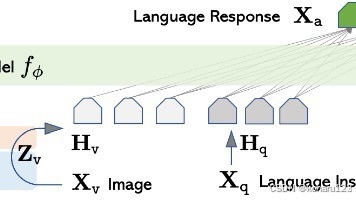
LLaVA论文提出了一种轻量高效的视觉指令微调方法,通过创新的数据生成和极简架构实现了接近多模态GPT-4的性能。
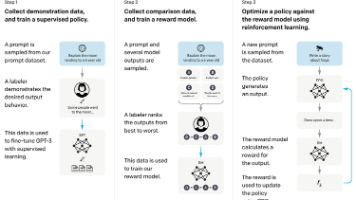
本文系统介绍了大语言模型后训练(Post-Training)的核心技术,包括SFT监督微调、RLHF强化学习对齐和DPO直接偏好优化。SFT通过高质量指令-回答对训练模型遵循指令;RLHF利用人类偏好数据训练奖励模型,通过PPO算法优化模型输出;DPO则简化了RLHF流程,直接优化偏好对差异。文章还介绍了DeepSeek-R1提出的GRPO新范式,特别适用于可验证推理任务。针对不同应用场景,作者提
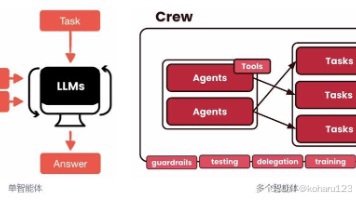
CrewAI是一个轻量级Python框架,用于构建和协调多智能体(AI Agent)协作系统。它通过角色分工和任务编排,模拟真实团队的工作流程。框架包含四个核心概念:Agent(定义角色和能力的智能体)、Task(具体工作任务)、Crew(协作团队)和Process(执行流程)。开发者可以轻松配置智能体的专业领域、工具集和使用的LLM模型,并通过任务依赖关系建立工作流。CrewAI支持动态参数输入
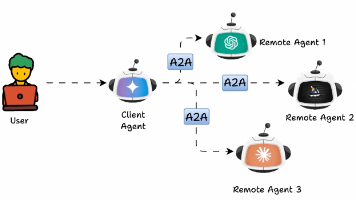
A2A协议摘要:该协议解决了多Agent系统的碎片化问题,通过定义统一通信规范实现跨平台互操作。
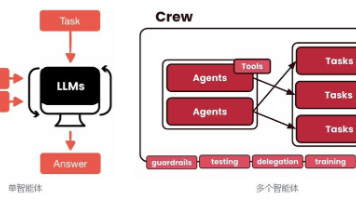
CrewAI是一个轻量级Python框架,用于构建和协调多智能体(AI Agent)协作系统。它通过角色分工和任务编排,模拟真实团队的工作流程。框架包含四个核心概念:Agent(定义角色和能力的智能体)、Task(具体工作任务)、Crew(协作团队)和Process(执行流程)。开发者可以轻松配置智能体的专业领域、工具集和使用的LLM模型,并通过任务依赖关系建立工作流。CrewAI支持动态参数输入
本文详细讲解了如何从零开始构建PyTorch数据加载管道。主要内容包括: 数据加载的核心流程:从原始文件到模型输入 Dataset和DataLoader的分工设计 实现自定义Dataset类处理图片分类任务 transforms预处理和数据增强技巧 DataLoader关键参数解析(batch_size、shuffle等) 处理文件损坏等边界情况 完整训练循环示例 CSV管理数据集等实用技巧 文章

本文系统介绍了大语言模型后训练(Post-Training)的核心技术,包括SFT监督微调、RLHF强化学习对齐和DPO直接偏好优化。SFT通过高质量指令-回答对训练模型遵循指令;RLHF利用人类偏好数据训练奖励模型,通过PPO算法优化模型输出;DPO则简化了RLHF流程,直接优化偏好对差异。文章还介绍了DeepSeek-R1提出的GRPO新范式,特别适用于可验证推理任务。针对不同应用场景,作者提
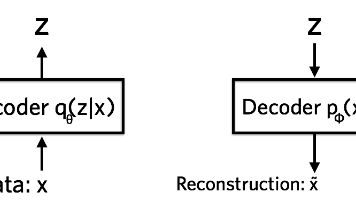
本文系统介绍了变分自编码器(VAE)的理论框架与实现细节。首先从普通自编码器的局限性出发,指出其潜空间缺乏结构性;随后引入概率视角,通过变分推断推导出证据下界(ELBO)目标函数,分解为重建项和正则项;详细讲解了VAE的神经网络实现,包括重参数化技巧和KL散度的解析解;最后分析了VAE生成图像模糊的原因。文章完整呈现了从基础自编码器到现代VAE的理论演进,为理解其在生成模型中的应用奠定基础。