




- @u012263509
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要: 会议慧眼(Meeting Eye)是一款基于AI眼镜的智能会议助手,通过多模态大模型自动拍摄并解析会议中的PPT/白板内容,生成结构化会议纪要。核心功能包括零操作记录、多模态识图(Qwen3-VL模型)、结构化输出(要点/决议/待办事项),解决传统会议中注意力分散、信息遗漏、整理耗时等痛点。其极简架构(仅3节点)支持端侧拍照与云端分析,直接输出可导入项目管理工具的JSON格式纪要,提升会议

《畅游通:AI眼镜上的智能旅行翻译助手》摘要 畅游通(Travel Mate)是一款基于AI眼镜的旅行翻译系统,通过多模态大模型实现"所见即译"。其核心创新在于:1)零操作自动翻译,用户佩戴眼镜即可识别外文字幕(菜单、路牌等);2)Qwen3.7-plus多模态模型不仅能翻译文本,还能分析上下文给出实用建议(如菜品辣度、路线指引);3)精简的三节点架构(眼镜拍照→模型处理→输出结果)确保快速响应。

摘要 本文详细记录了作者使用华为云码道IDE在三天内从零开发鸿蒙原生瘦身应用《燃烧肥肉》的全过程。该应用包含体重记录、卡路里收支、运动计划和趋势图表四大功能模块,完全通过智能体对话生成代码实现。文章分步骤介绍了开发流程:从IDE安装配置、鸿蒙项目创建、智能体需求解析,到具体功能实现(包括关系型数据库搭建、ArkUI组件应用、数据可视化图表绘制等)。重点展示了码道IDE的智能代码生成能力,特别是其鸿
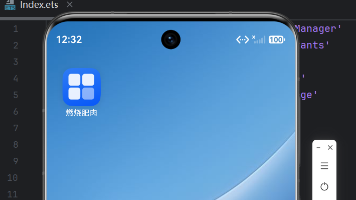
摘要 本文详细记录了作者使用华为云码道IDE在三天内从零开发鸿蒙原生瘦身应用《燃烧肥肉》的全过程。该应用包含体重记录、卡路里收支、运动计划和趋势图表四大功能模块,完全通过智能体对话生成代码实现。文章分步骤介绍了开发流程:从IDE安装配置、鸿蒙项目创建、智能体需求解析,到具体功能实现(包括关系型数据库搭建、ArkUI组件应用、数据可视化图表绘制等)。重点展示了码道IDE的智能代码生成能力,特别是其鸿
但你只要让它接手 3 个月以上的项目,就会看到一个奇怪的现象:**逻辑是对的,结构却在一点点变形,能跑但越来越难维护。**这不怪 AI,它没有生活经验,也没有技术债务意识。那种爱恨交织的感觉特别熟悉,因为我们每个人都有过这种经历——系统崩了,客户在问,领导在追,自己在凌晨修,熬过危机的那一秒你喊老子不干了,等服务恢复又默不作声继续上线下一个版本。Cloudflare 倒下的这三个小时,让我忽然意识

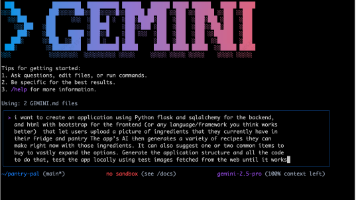
摘要:Google发布Gemini 3 Pro模型,在多项基准测试中全面领先,包括数学推理(AIME 2025满分)、长文本处理(1M token无压力)和多模态理解(视频分析准确率95%)。实测显示其代码生成能力远超GPT-5.1和Claude 4.5,47秒即可完成React+Flask全栈应用开发。模型已集成至Google搜索、Gemini应用和Vertex AI平台,企业版成本比竞品低20
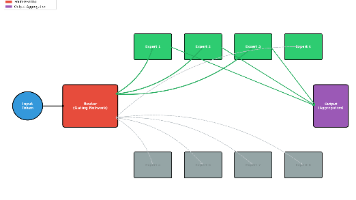
本文探讨了智能化技术在10个业务场景中的应用方案。在高并发客服系统中,通过分层处理和意图识别优化响应速度;电商领域利用模板化生成实现商品描述的批量生产;教育行业可定制个性化习题及解析。此外,还覆盖了短视频脚本创作、跨语言本地化翻译、代码辅助生成、热点内容生产、企业知识库问答、数据清洗标注以及多模态任务处理等场景。这些方案通过引入智能引擎重构传统工作流,在保持低成本的同时显著提升效率,为各类业务瓶颈
2026年4月24日,DeepSeek V4与GPT-5.5同日发布,标志着AI领域的新一轮竞争。DeepSeek V4采用MoE架构,1.6万亿参数中仅激活少量专家,大幅降低推理成本,原生支持100万token长上下文处理,成本仅为GPT-4o的1/20。通过CSA和HCA模块协同,V4在长文本理解、代码生成和数学推理上表现突出,尤其在性价比和国产算力适配方面优势显著。然而,它在多模态、复杂推理
我一直在做一个AI面试官的项目,用DeepSeek做后端,效果还行,但总觉得哪里不对。候选人面对一个对话框打字,那种感觉就像在跟ATM机聊天,毫无压迫感,也毫无真实感。直到我发现了魔珐星云。说实话,一开始我是抱着试试看的心态注册的。毕竟市面上数字人产品我见多了,要么延迟高到让人想摔手机,要么画质糊得像上世纪的摄像头。但这次不太一样,我花了大概两个小时,就把一个纯文本的AI面试官,升级成了一个有表情
我一直在做一个AI面试官的项目,用DeepSeek做后端,效果还行,但总觉得哪里不对。候选人面对一个对话框打字,那种感觉就像在跟ATM机聊天,毫无压迫感,也毫无真实感。直到我发现了魔珐星云。说实话,一开始我是抱着试试看的心态注册的。毕竟市面上数字人产品我见多了,要么延迟高到让人想摔手机,要么画质糊得像上世纪的摄像头。但这次不太一样,我花了大概两个小时,就把一个纯文本的AI面试官,升级成了一个有表情