




- @u011453680
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Openclaw远程控制UI可通过本地回环或HTTPS/Tailscale访问,如需HTTP需修改配置文件允许不安全认证。默认会话模型在配置文件中指定,也可在会话中临时切换模型。配置文件路径为~/.openclaw/openclaw.json,需确保指定模型已在providers中列出。

【代码】安装mmcv-full时报错:Could not build wheels for mmcv-full, which is required to install pyproject.toml-bas。

【代码】ubuntu20.04自动封禁恶意ip代码与设计思路。

预训练在相似任务中,由于神经网络模型的浅层是通用的,如下图:所以当我们的数据集不够大,不能产生性能良好的模型时,可以尝试让模型B在用模型A的浅层基础上,深层的部分自己生成参数,减小数据集的压力使用模型A的浅层来实现任务B,由两种方式:冻结(frozen):浅层参数不变微调(Fine-Tuning):浅层参数会跟着任务B的训练而改变总结:一个任务A,一个任务B,两者极其相似,任务A已经通过大数据集训

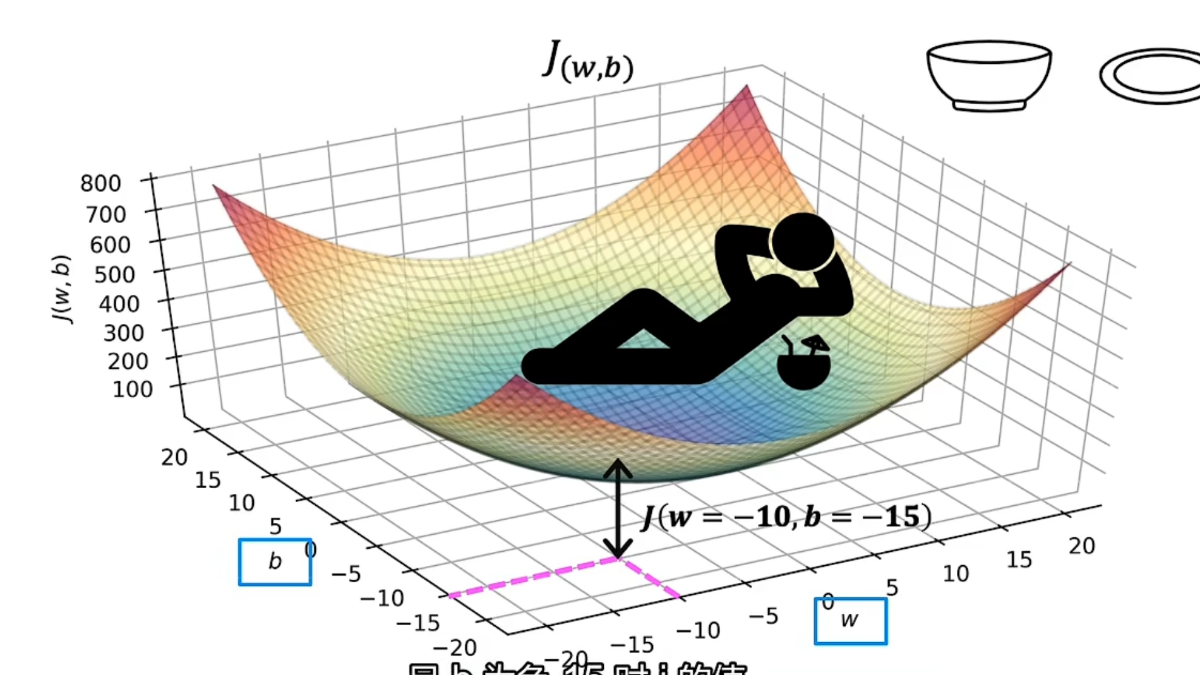
梯度下降我们可以用一种更系统的方法,来找到一组w,b,使成本函数的值最小。这个方法叫梯度下降,它可用于最小化任何函数,不仅仅包括线性回归的成本函数,也包括两个以上参数的其他成本函数在线性回归中,w和b的初始值是多少并不重要,所以通常将他们的初始值设为0。成本函数并不总是弓形或吊床行的函数,这代表他可能有两个及以上的最小值梯度下降的步骤:a. 初始化w和b的值,通常设为0b. 继续更改w和b的值,来
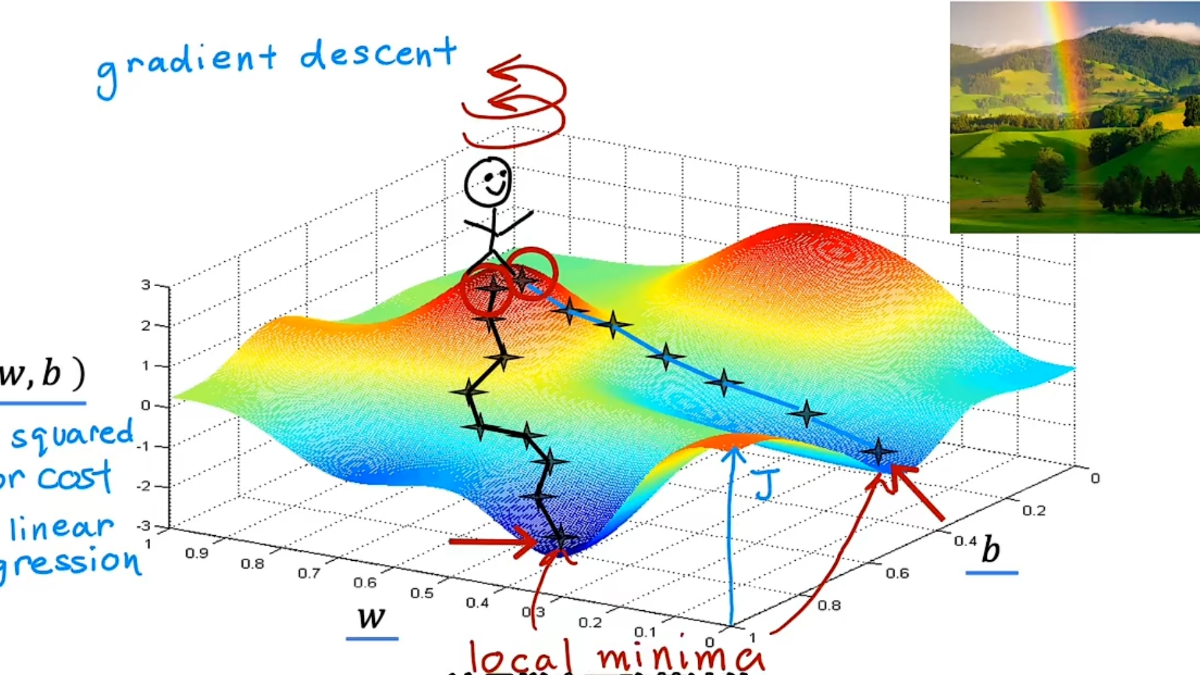
成本函数平方误差成本函数是最通常用于线性回归的成本函数最终,我们要找到一组w和b,让j函数的值最小误差:ŷ - y简化后的平方误差成本函数,即b = 0当w = 1时,f(x) = x,J(1) = 0左侧为f(x)函数,X轴为x,❌表示训练示例右侧为J(w)函数,X轴为w当w = 0.5时,f(x) = 0.5x,J(0.5) ≈ 0.58当w = 0时,f(x) = 0,J(0) ≈ 2.3以
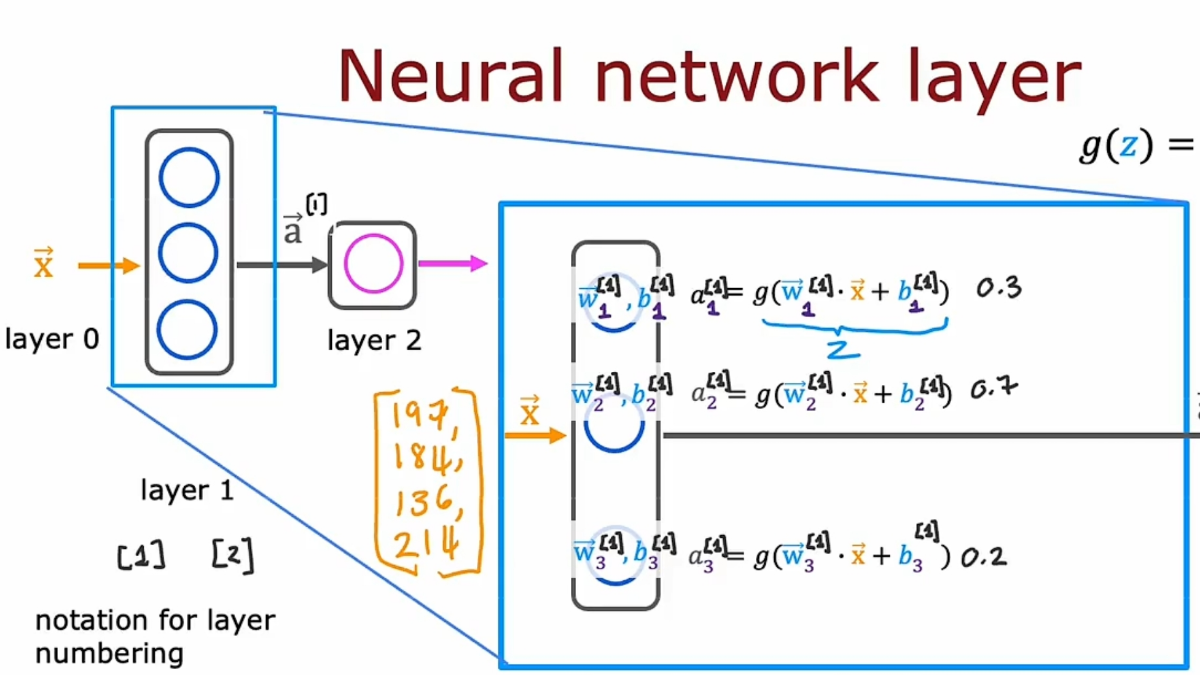
隐藏层的内部实现
逻辑回归的梯度下降

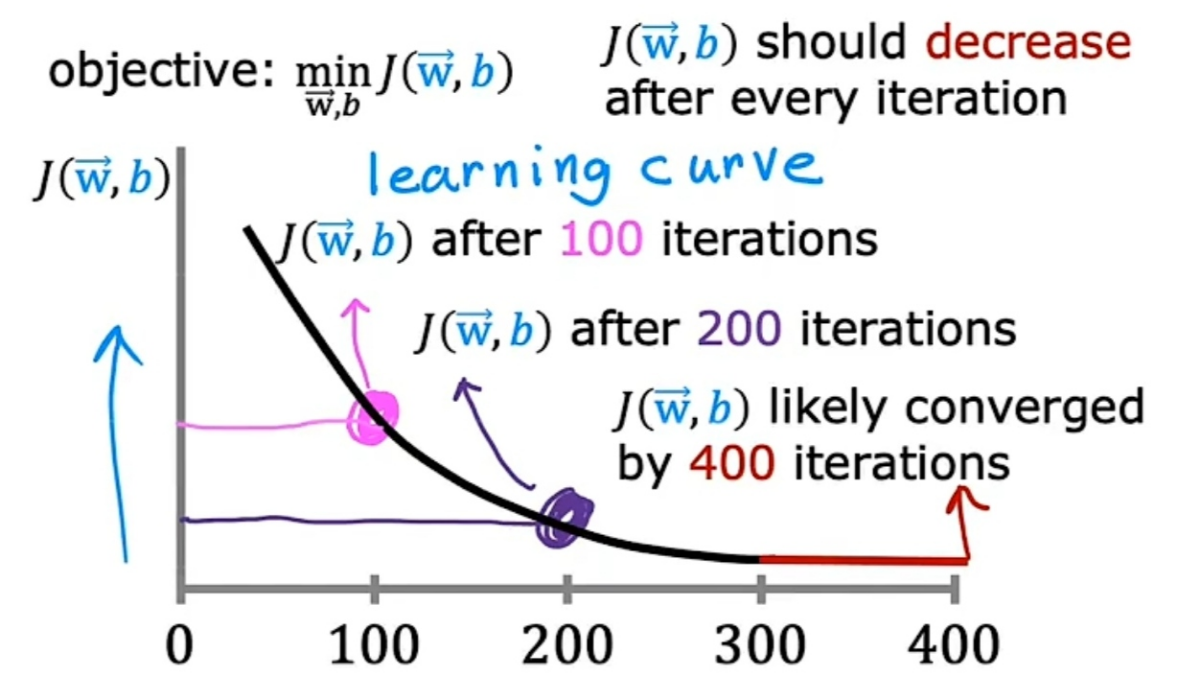
画学习曲线图x轴是梯度下降算法的迭代次数,y轴是成本函数J的值梯度下降算法的目的是:找到一组w和b,让成本函数J最小学习曲线图可以帮助我们查看成本函数J如何变化。如果梯度下降算法工作正常,那么成本函数J在每次迭代后都会减少。如果成本函数J在一次迭代后增加,那意味着学习率α可能选的太大,或代码有bug。学习曲线图还可以帮助我们判断,梯度下降算法是否收敛。当学习曲线平坦时,梯度下降算法收敛。自动收敛测
正则化的思想如果特征的参数值更小,那么对模型有影响的特征就越少,模型就越简单,因此就不太容易过拟合如上图所示,成本函数中有W₃和W₄,且他们的系数很大,要想让该成本函数达到最小值,就得使W₃和W₄接近0,从而消除它们对成本函数的影响,最后我们就得出一个接近二次函数(左边图片)的成本函数正则化的一般形式通常,一个模型有很多特征,我们不知道哪个特征的参数重要,哪个特征的参数我们需要缩小或惩罚。所以,我
