




- @tanixn
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在这里就可以看到很多可下载的文件。一般来说,下载需要下载箭头标注的这几个文件。其中“pytorch_model.bin”是基于pytorch框架的模型文件,有时候也会有tf_model的模型文件。根据自己的框架进行选择。在Hugging Face上搜索到自己想要的模型,这里我自己搜索的是检索增强常用的模型。搜索到之后,点击“files and versions”。下载之后将其放在同一个文件
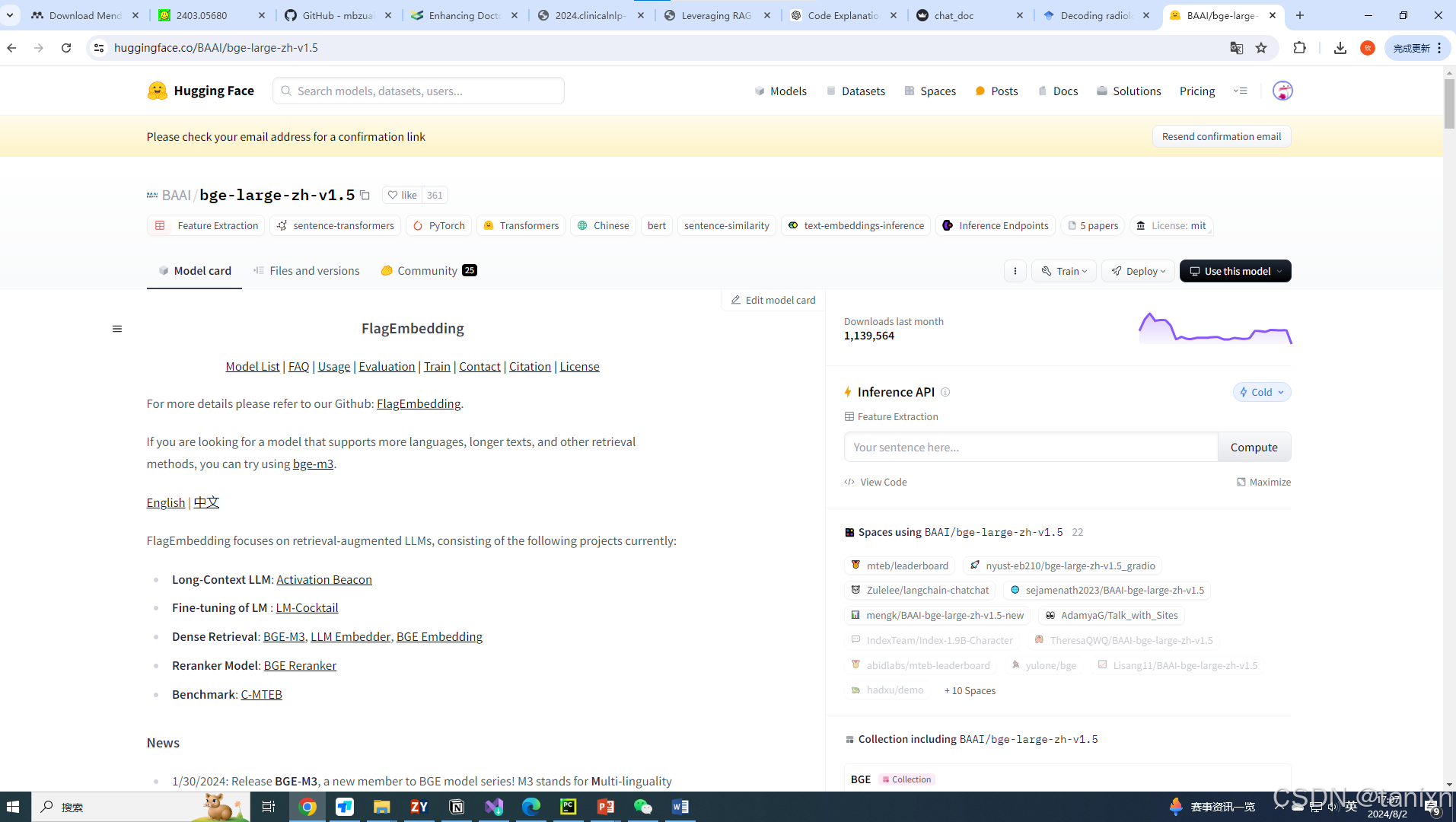
因为某些未知的原因。docker运行一段时间后,突然gpu掉线,输入nvidia-smi。(如下图)看了很多解决方法,但是大多数都要重启系统或者服务器或者docker,但是镜像源是公共的,服务器也不好重启。因此重新建立一个pod并且安装上所有需要的包。担心还有下一次这样的问题出现,这里记录一下配置的过程和安装的所有命令。方便下一次重新配置。pod的配置填写好1:镜像源;2:命名空间;3:持久卷;4
中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/阿里云 http://mirrors.aliyun.com/pypi/simple/豆瓣(douban) http:/

模型的训练需要大量的音频。鉴于国语与粤语的区别,因此我只选择了其中44首国语歌曲,尝试训练一下国语版的eason。这里需要用到一个github上开源的工具--slpeeter。通过这个工具,可以直接去分离人声与背景音乐,非常方便。另外,分离背景音乐与人声需要用到该工具下的双声道模型。将压缩包解压后将其中的模型复制到SpleeterGUI文件夹中的pretrained_models文件夹中(见上图)
我已经通过remote-ssh连接上了实验室的服务器,但是如果通过这个插件上传数据的话,一方面不支持上传文件夹,另一方面上传速度太低。之前拖动一个数据集子集就已经把电脑完全卡死。我通过百度网盘下载了大概200GB的LUNA-2016的肺结节CT数据。实验是在实验室服务器上进行的,我现在需要将本地的数据集传输到实验室的服务器上。现在通过scp命令来上传数据集。以后所有大型的数据传输都可以使用这个命令
我已经通过remote-ssh连接上了实验室的服务器,但是如果通过这个插件上传数据的话,一方面不支持上传文件夹,另一方面上传速度太低。之前拖动一个数据集子集就已经把电脑完全卡死。我通过百度网盘下载了大概200GB的LUNA-2016的肺结节CT数据。实验是在实验室服务器上进行的,我现在需要将本地的数据集传输到实验室的服务器上。现在通过scp命令来上传数据集。以后所有大型的数据传输都可以使用这个命令
创建成功之后,点击进入jupyter(见下面第一张图),如果想看一下详情,可以把这个“请先看我”的记事本看完,也可以选择文档快速开始。我所用的电脑显卡算力不足,因此我选择了一个算力云服务平台。大家可以根据需要自行选择是在本地训练还是云端租卡训练。这是使用的是github上一个开源的音频转换的模型。这个路径下创建文件夹,将之前处理好的音频文件直接拖到这个界面中上传。在云平台上可以选择社区镜像,这里直
因为项目需要配置环境变量,第一次操作。在论坛上找了很久,都是扯淡。说什么要在桌面用记事本创建一个1.env文件,然后再命令行里面rename,将文件名改为.env。其实只要在pycharm里面直接新建文件,然后命名为.env就可以了。

这个报错是因为你的输入数据和模型参数的数据类型不匹配。选择其中一种方法,确保数据类型一致即可。: 如果你更想保持输入数据的。),而模型的参数默认是。
