




- @taifyang
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
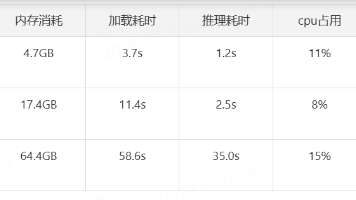
摘要:本文介绍了在Jetson Thor上搭建Qwen3-VL-2B-Instruct模型环境的详细步骤。主要包括:1)通过特定源安装PyTorch及相关库;2)解决常见依赖缺失问题(如libnvpl_lapack、libcublas等);3)提供完整的Python实现代码,展示如何加载多模态视觉语言模型Qwen3VL,并实现物体检测功能。代码包含图像预处理、模型推理、结果解析和可视化模块,特别处
本文介绍了如何使用TensorRT-LLM加载Qwen2-VL-2B-Instruct多模态模型进行图像理解任务。主要内容包括:1) 搭建环境并下载模型;2) 编写测试代码加载图像和处理器;3) 构建包含视觉占位符的prompt;4) 设置生成参数进行推理。测试结果显示模型能正确识别图片内容,但过程中出现了PyTorch版本兼容性警告。代码修复了图像输入格式问题(需用列表包裹),最终成功输出了对测
本文介绍了使用vLLM框架部署Qwen2-VL-2B-Instruct模型的过程。通过运行vLLM serve命令启动服务,系统显示模型版本为0.19.0,采用torch.bfloat16数据类型,最大序列长度为32768。日志信息包含模型初始化配置、异步调度启用提示,以及图像处理器类型变更警告。输出还展示了引擎初始化参数,包括并行处理设置、量化选项和动态形状配置等详细信息。整个过程展示了如何使用

摘要:本文提出将原始SAM3D中的SAM模型替换为FastSAM模型,构建FastSAM3D系统,并通过ONNXRuntime或TensorRT框架部署以提升推理速度。代码实现了基于FastSAM的图像分割、点云处理和3D重建流程,包括ONNX模型推理、深度图与彩色图对齐、点云坐标转换及分组处理等功能。该系统通过优化后的模型架构和部署方案,显著提高了3D场景理解任务的执行效率。

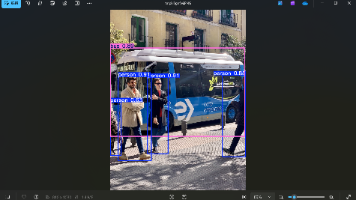
摘要:本文介绍了如何配置Ultralytics YOLOv8.4.2环境并进行模型训练和推理。首先从GitHub下载官方代码,安装指定版本的PyTorch和依赖项。环境配置完成后,通过Python脚本加载预训练的YOLO26n模型,展示模型信息,并在COCO8数据集上进行100个epoch的训练。最后使用训练好的模型对示例图像"bus.jpg"进行目标检测推理并可视化结果。整个
本文实现了一个通用的相机采集框架,包含抽象基类BaseCamera和USB相机实现USBCamera。BaseCamera定义了相机初始化、图像采集、线程管理等通用接口,采用生产者-消费者模式,通过线程安全队列缓存图像数据。USBCamera继承BaseCamera,基于OpenCV实现具体功能,支持设置分辨率、帧率等参数。框架采用多线程设计,主线程通过get_frame()获取图像,采集线程持续
本文介绍了在Docker环境下配置和运行YOLOv7模型推理的步骤。首先从GitHub下载yolo_deepstream源代码,并按照指南配置Docker环境。在编译过程中遇到了问题,通过修改Makefile中的编译参数(包括CUDA路径和依赖库)得以解决。接着下载YOLOv7模型文件,并修改配置文件以适配该模型。最后运行deepstream-app命令启动推理,成功加载模型并生成引擎文件。日志显
经过试验,LZ发现使用yolov8n(检出47辆)、yolov8s(检出51辆)等小模型时会发生车辆漏检,而yolov8m及更大的模型能检测出所有通过的52辆车。

本文展示了使用Open3D库实现多尺度ICP配准的方法。通过源点云和目标点云("cloud_bin_0.pcd"和"cloud_bin_1.pcd"),设置不同体素大小、收敛准则和最大对应距离进行多尺度ICP配准。程序分别在CPU和CUDA设备上运行,记录运行时间和配准精度(fitness和inlier RMSE)。结果显示,迭代过程中fitness从64.

https://blog.nowcoder.net/n/bd4413ee94f449949511b01b97df7775