




- @sunbaigui
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
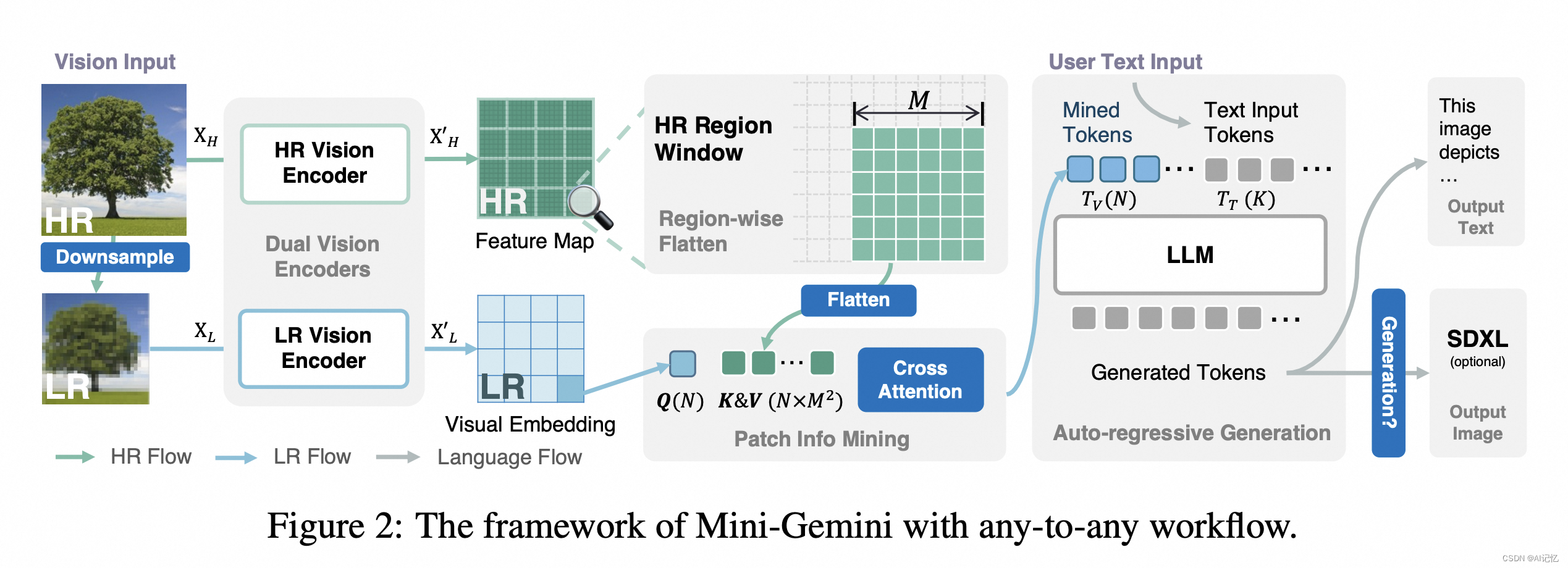
最近,一篇名为“Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models”的文章在arXiv上发表,为我们展示了一个简单而有效的框架,旨在提升多模态视觉语言模型(VLMs)的性能。它即能直接提升图像感知能力,也能作为多模态环境下图像生成任务的前置prompt生成器。主要探索了如何增强图像全局感受野,以及探索
vgg和googlenet是2014年imagenet竞赛的双雄,这两类模型结构有一个共同特点是go deeper。跟googlenet不同的是,vgg继承了lenet以及alexnet的一些框架,尤其是跟alexnet框架非常像,vgg也是5个group的卷积、2层fc图像特征、一层fc分类特征,可以看做和alexnet一样总共8个part。根据前5个卷积group,每个group中的不同配置,
AIGC元年达到了学术-商业共振,本文介绍现有AI绘画、AI作画背后的相应基本原理、应用、以及论文参考文献。

AIGC大模型在人工智能领域取得了重大突破,涵盖了LLM大模型、多模态大模型、图像生成大模型以及视频生成大模型等四种类型。这些模型不仅拓宽了人工智能的应用范围,也提升了其处理复杂任务的能力。a.) LLM大模型通过深度学习和自然语言处理技术,实现了对文本的高效理解和生成;b.) 多模态大模型则能够整合文本、图像、声音等多种信息,实现跨模态的交互和理解;c.) 图像/视频生成大模型则进一步将AI技术

django之sqlite3常见错误
vgg和googlenet是2014年imagenet竞赛的双雄,这两类模型结构有一个共同特点是go deeper。跟googlenet不同的是,vgg继承了lenet以及alexnet的一些框架,尤其是跟alexnet框架非常像,vgg也是5个group的卷积、2层fc图像特征、一层fc分类特征,可以看做和alexnet一样总共8个part。根据前5个卷积group,每个group中的不同配置,
inception v2与inception v3两种模型配置。Inception v3单模型达到了21.2%的top1错误率,多模型达到了17.3%的top1错误率
为了进一步拓展写真风格的多样性和使用便捷性,在最新版本的FaceChain中,开源了人像写真风格LoRA模型的自定义训练和共享功能,通过将模型上传至风格广场的形式,使得海量写真风格实现共享社区一键式调用,走向风格化人像写真新纪元。

vgg和googlenet是2014年imagenet竞赛的双雄,这两类模型结构有一个共同特点是go deeper。跟googlenet不同的是,vgg继承了lenet以及alexnet的一些框架,尤其是跟alexnet框架非常像,vgg也是5个group的卷积、2层fc图像特征、一层fc分类特征,可以看做和alexnet一样总共8个part。根据前5个卷积group,每个group中的不同配置,
AIGC元年达到了学术-商业共振,本文介绍现有AI绘画、AI作画背后的相应基本原理、应用、以及论文参考文献。