




- @software_0215
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
原则核心目的一句话口诀单一职责类只做一件事职责单一,不要“一专多能”开闭原则不修改核心,只扩展对扩展开放,对修改关闭里氏替换子类不破坏父类契约子类型必须能替换父类型依赖倒置面向接口,不面向实现依赖抽象,别依赖具体接口隔离接口要小而精不要臃肿接口,按需隔离迪米特法则减少对象间直接耦合只和朋友说话,别找陌生人合成复用组合优于继承多用组合少用继承这七大原则不是孤立存在的,它们相互补充。开闭原则是终极目标
k8s 1.28版本不允许在单独装docker,通过k8s 制作镜像,完全没问题!K8s 1.28 +(没有 docker)照样能把你的 SpringBoot Jar 做成镜像!我给你一行命令都不用改,亲测可用!
3 节点 All-in-One 高可用 K8s高可用 etcd高可用 master3 台都能跑业务无单点故障企业生产标准架构。
Spring MVC的请求处理是围绕的找路 → 适配 → 执行 → 返回 → 解析 → 渲染 → 响应九步曲。的启动是从main方法开始,创建并执行run方法,最终创建并刷新 IoC 容器、启动内嵌 Web 服务器。Spring IoC的核心是Bean 的完整生命周期管理,并通过和提供扩展点。通过一系列安全过滤器链,在请求到达 Controller 前完成认证和授权两个核心阶段。Spring AO
Spring MVC的请求处理是围绕的找路 → 适配 → 执行 → 返回 → 解析 → 渲染 → 响应九步曲。的启动是从main方法开始,创建并执行run方法,最终创建并刷新 IoC 容器、启动内嵌 Web 服务器。Spring IoC的核心是Bean 的完整生命周期管理,并通过和提供扩展点。通过一系列安全过滤器链,在请求到达 Controller 前完成认证和授权两个核心阶段。Spring AO
大模型微调的关键不在于复杂的代码,而在于高质量的数据 + 合适的微调方法 + 正确的超参数。对于大多数开发者,推荐LoRA/QLoRA + Hugging Face PEFT + 小型专用数据集,可以在消费级显卡上快速得到效果不错的垂直领域模型。如果追求极致效果且资源充足,才考虑全量微调。如果需要更深入解释某个环节(例如数据构造细节、LoRA 原理、评估方法等),可以继续问我。
大模型微调的关键不在于复杂的代码,而在于高质量的数据 + 合适的微调方法 + 正确的超参数。对于大多数开发者,推荐LoRA/QLoRA + Hugging Face PEFT + 小型专用数据集,可以在消费级显卡上快速得到效果不错的垂直领域模型。如果追求极致效果且资源充足,才考虑全量微调。如果需要更深入解释某个环节(例如数据构造细节、LoRA 原理、评估方法等),可以继续问我。
一、建立Maven工程pom.xml文件的 dependencies内加入<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client --><dependency><groupId>org.apache.hadoop</groupId><artifactId&g
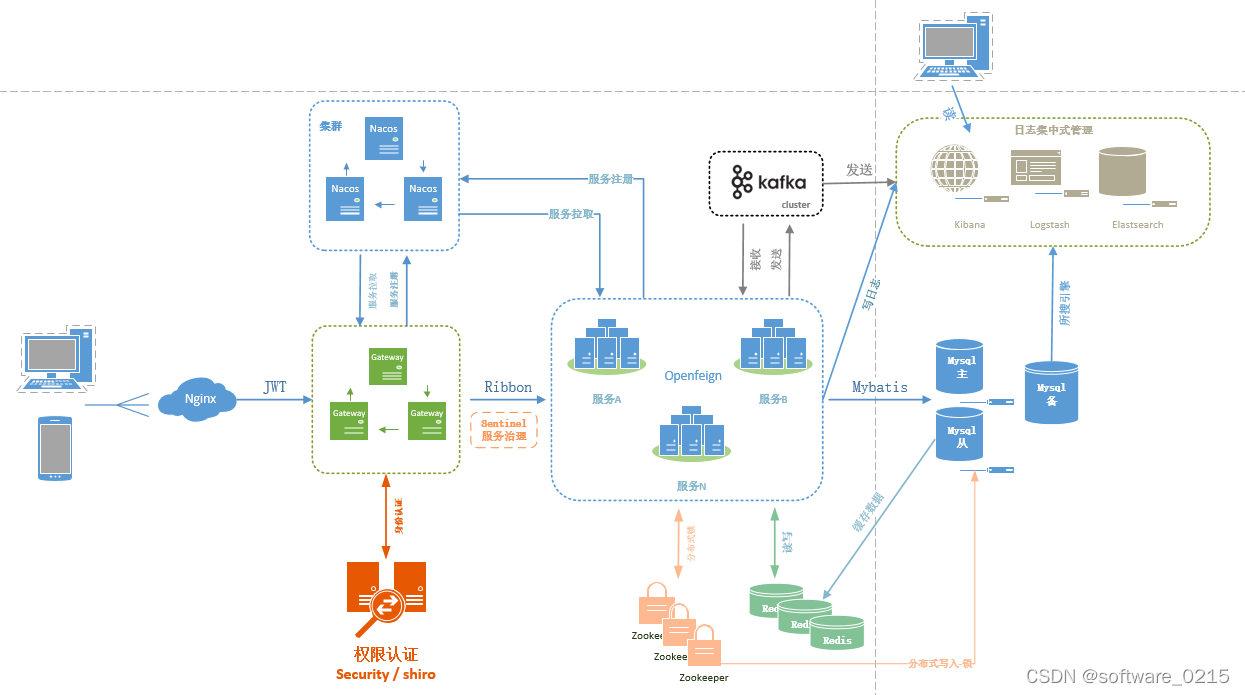
由于项目突发,时间急迫,初步构建了一个基于微服务的平台架构,涉及到了springcloud和alibaba的一些技术框架,因为新启盘,先弄个简单点的吧。就一个visio,图画的实在是有点糙啊,好在意思表达清楚了!!项目结构(一)拓扑图(二)服务器清单(三)好久没有搭建架构了,算是小试牛刀一把。...
RAG(检索增强生成)技术的核心流程包含Prompt设计,Prompt在其中起到关键作用。