- @secext2022
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
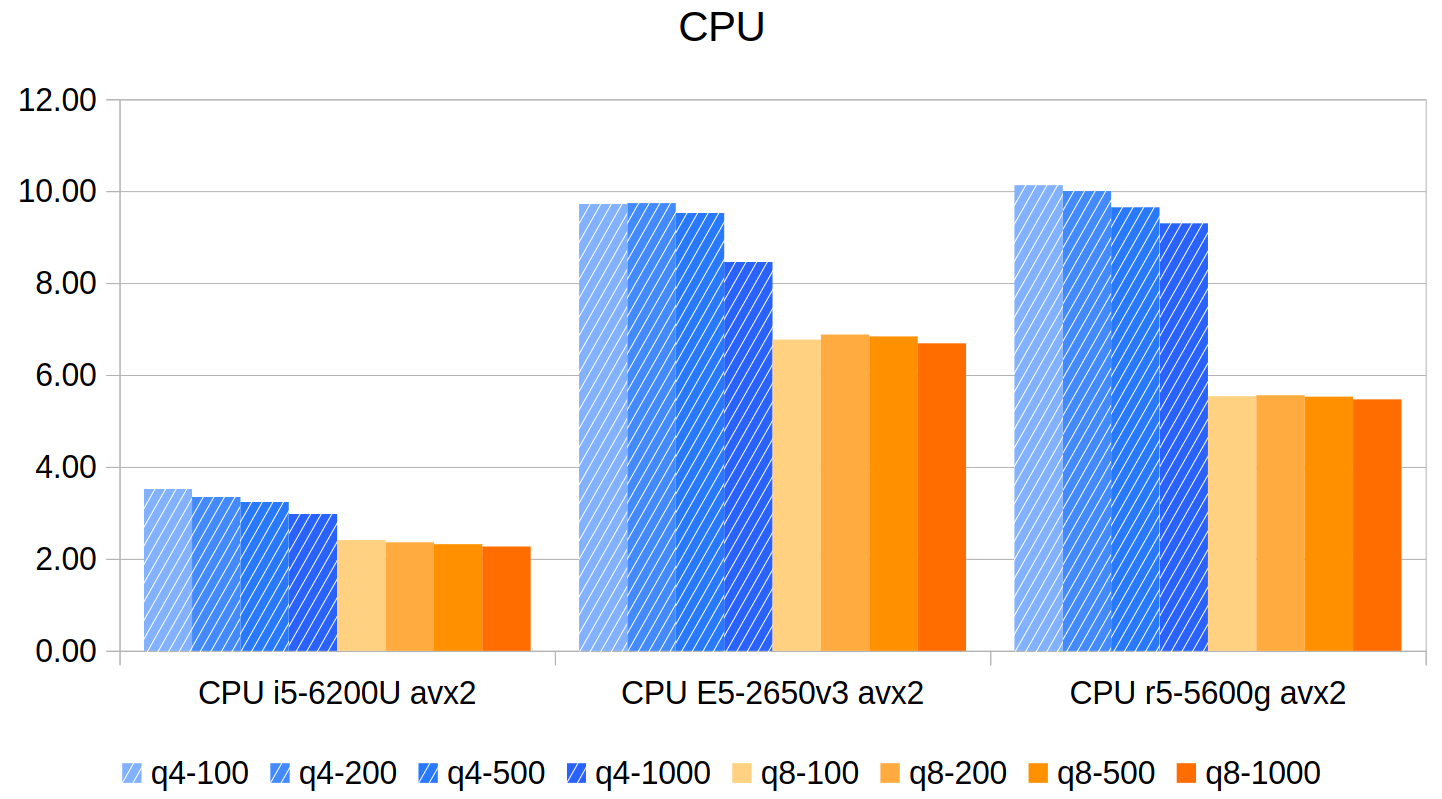
本文使用容器 (podman) 编译了 llama.cpp 的 vulkan 后端和 SYCL 后端, 并成功在 Intel GPU (A770) 运行, 获得了较快的语言模型推理速度.SYCL 后端比 vulkan 后端稍微快一点, 但不多. 使用的模型 (gguf), 生成长度, 软件驱动版本, 运行参数设置等很多因素, 都可能影响模型推理的速度, 所以本文中的运行速度仅供参考.SYCL 比

本文实现了一个很简陋的 AI agent, 可以调用 deepseek API 和上一篇文章中的 MCP 工具 (mcp-run) 来执行任务. agent 的工作原理并不复杂, 主要是一个调用大模型 API 以及 MCP 工具的循环.目前的 AI 本质上不可靠, 所以在虚拟机中运行 AI 可以获得较高的安全程度 (当然也不是绝对安全).让 AI 自举, 也就是用 AI 编写给 AI 调用的 MC
MCP 工具调用就是这么简单.以前的 AI 聊天, 就像 AI 只有嘴, 只能做 嘴强王者. 现在的 agent, 相当于给 AI 装上了手脚, 让 AI 可以调用工具, 执行操作, 所以能力边界一下就扩展了.展望未来, 当 AI +机器人成熟之后, AI 就可以从屏幕中走出来了 (狗头).本文中实现的 MCP 工具非常简陋, 只是一个粗糙的原型.如果要用于实际用途, 还需要大量的完善优化. 主要
本文使用 AI 写了一个很简单的程序代码, 实现了通过 SSH 在同一个 Linux 虚拟机中转发消息的功能.这不仅测试了 AI 写代码的能力, 也了解了 订阅/发布 这种常见的模型. 是一次很愉快的玩耍哟 ~
(本文使用 AI 辅助创作)注: 下面的内容被其所描述的方式处理过了: (狗头)

本文实现了一个很简陋的 AI agent, 可以调用 deepseek API 和上一篇文章中的 MCP 工具 (mcp-run) 来执行任务. agent 的工作原理并不复杂, 主要是一个调用大模型 API 以及 MCP 工具的循环.目前的 AI 本质上不可靠, 所以在虚拟机中运行 AI 可以获得较高的安全程度 (当然也不是绝对安全).让 AI 自举, 也就是用 AI 编写给 AI 调用的 MC
MCP 工具调用就是这么简单.以前的 AI 聊天, 就像 AI 只有嘴, 只能做 嘴强王者. 现在的 agent, 相当于给 AI 装上了手脚, 让 AI 可以调用工具, 执行操作, 所以能力边界一下就扩展了.展望未来, 当 AI +机器人成熟之后, AI 就可以从屏幕中走出来了 (狗头).本文中实现的 MCP 工具非常简陋, 只是一个粗糙的原型.如果要用于实际用途, 还需要大量的完善优化. 主要
本文主要内容: 在香橙派 zero3 (1GB) 上安装 adguardhome 的过程.adguardhome 作为一个 DNS 服务器, 安装简单, 配置方便, 界面美观 (web), 可以加速上网.adguardhome 虽然不需要太多计算存储资源, 但还是需要那么一点的. 常见的 OpenWrt 路由器的存储空间往往太小 (比如 256MB RAM,28MB flash), 运行 adgu
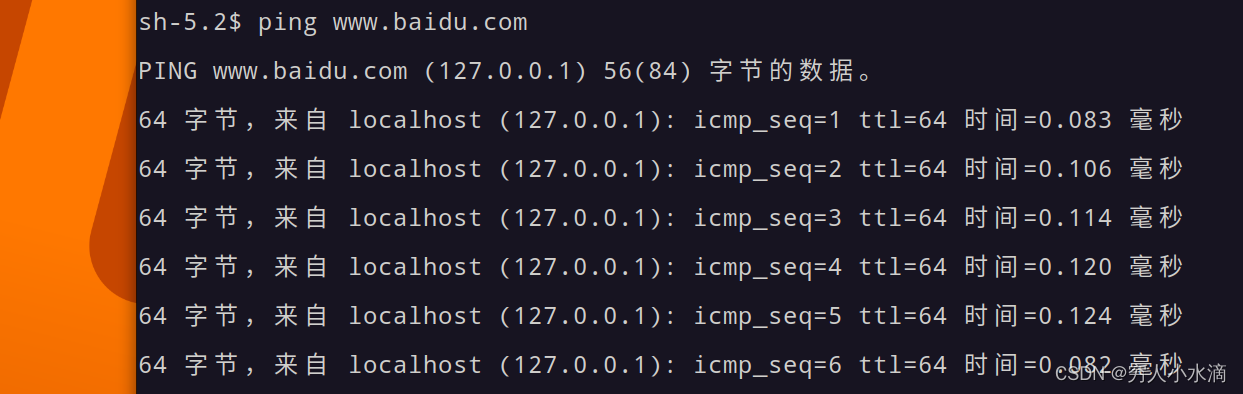
本文验证了在容器中运行 QEMU/KVM 虚拟机是可行的, 可以正常使用 Linux 内核的 KVM 硬件加速. podman 可以普通用户运行, 无需 root 权限, 所以普通用户也可以运行 QEMU/KVM 虚拟机.

由于本文太长, 分开发布, 方便阅读.