




- @roadtohacker
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
文章摘要: 大模型长对话场景中,KV Cache和Prompt Caching技术能显著降低Token消耗成本。KV Cache通过缓存历史token的K/V向量,避免生成式模型重复计算,将复杂度从O(n²)降至O(n)。Prompt Caching进一步实现跨请求复用,通过前缀匹配复用系统提示等固定内容的KV Cache,如OpenAI等API会自动统计缓存命中量(返回cached_tokens
文章摘要: 大模型长对话场景中,KV Cache和Prompt Caching技术能显著降低Token消耗成本。KV Cache通过缓存历史token的K/V向量,避免生成式模型重复计算,将复杂度从O(n²)降至O(n)。Prompt Caching进一步实现跨请求复用,通过前缀匹配复用系统提示等固定内容的KV Cache,如OpenAI等API会自动统计缓存命中量(返回cached_tokens
golang的sync包提供了一些并发控制的工具,在应用程序开发过程中是非常有用的,下面详细介绍下这些工具的原理和使用在介绍工具之前,先讲解下内存模型中的关系// 示例:Happens-Before关系a = "hello, world" // 写操作Adone = true // 写操作Bgo setup()for!done { // 读操作C// 忙等待print(a) // 读操作D关键点如
【代码】golang slice原理。
eino是字节推出的LLM应用开发框架,它使用golang作为开发语言,提供了众多的支持LLM应用开发的工具,下面介绍下这个框架的逻辑,以及如何开发一个ai agent,并集成到现有的项目内,以及调用大模型的过程中遇到的一些问题官网已经给出了一些使用的示例,可以参考搭建一个简单的LLM聊天功能框架支持的内容比较丰富,除了支持Agent,还支持Chain、Graph等组件,但我们这次主要说Agent
2022年,一幅由AI生成的画作《太空歌剧院》在艺术比赛中击败人类选手夺冠,震惊了世界。这幅画细节丰富、意境悠远,很难想象它出自一个没有感情的机器之手。与此同时,ChatGPT能写出流畅的诗歌,Midjourney能生成"赛博朋克风格的猫",GitHub Copilot能帮程序员自动补全代码……这些AI不再只是"识别"或"分类"数据,而是能。这就是生成式AI(Generative AI)的革命——

向量(Vector)是一串数字,代表数据的"语义特征"。文字"猫"的向量可能是 [0.2, 0.5, -0.3, …](512个数字)文字"狗"的向量可能是 [0.3, 0.4, -0.2, …]相似的语义,向量会更"像"(数字差异小)生成向量的过程叫"嵌入(Embedding)",就像给数据拍X光片——表面看是文字/图片,实际是一串能被AI理解的数字。

在SVM中,离分隔线最近的那些点(草莓或蓝莓)被称为"支持向量"(Support Vectors)。它们是决定分隔线位置的关键——就像拔河比赛中最靠近中间线的那些人,是胜负的关键。如果移动非支持向量的点,分隔线不会变;但如果移动支持向量,分隔线就必须重新计算。所以SVM只"关心"那些离分隔线最近的点,这让它在处理高维数据时非常高效。

还记得以前我们怎么用ChatGPT吗?这时候的AI,更像一个**“军师”(只动嘴不动手)**。而,就是给"军师"装上了**“手脚”(工具)"眼睛"(感知)主动行动**——帮你打开APP、点击按钮、填写表单、完成支付。
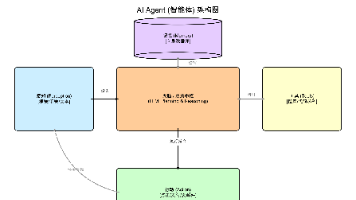
在人工智能飞速发展的今天,我们见证了无数强大的AI Agent(智能体)的诞生。然而,当我们需要解决复杂问题的时候,往往发现这些Agent就像一个个孤岛,被禁锢在各自的框架和生态中,无法协同工作。接下来我们主要探讨下一个旨在打破这些壁垒的开放标准,协议。A2A协议是一个开放标准,旨在实现AI Agent之间的无缝通信与协作。它提供了一种通用的语言,让基于不同框架,如。