- @riririch
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
x1y1x2y2xnynxi∈Rdyi∈−11{(x1y1x2y2xnyn)}xi∈Rdyi∈−11wTxb0wTxb0使得所有训练样本被完全正确分类,并且分类间隔最大。对所有样本i12ni12...nyiwTxib≥1yiwTxib≥1这表示:如果yi1y_i = +1yi1,则。
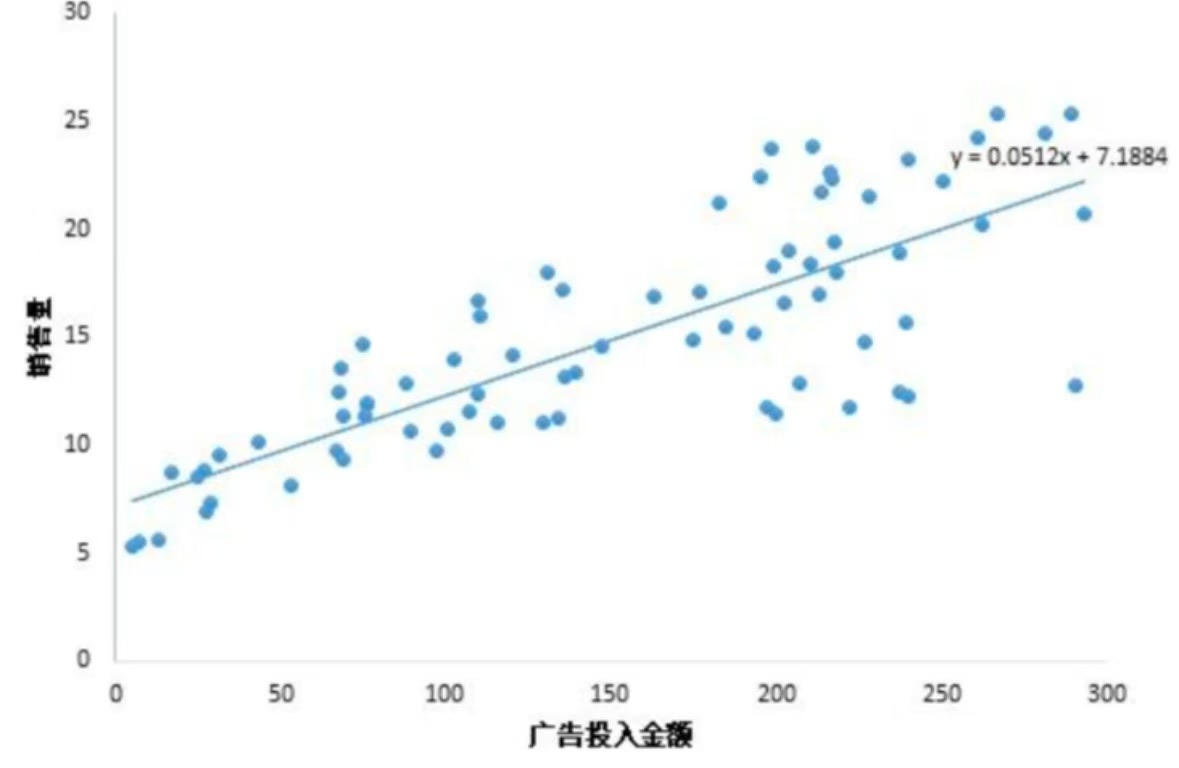
线性回归的基本思想是通过拟合最佳直线(也就是线性方程),来描述自变量和因变量之间的关系。这条直线被称为回归线,其目的是使得所有数据点到这条直线的垂直距离(即残差)的平方和最小。这个最小化过程通常称为最小二乘法。学习二元一次方程时,我们通常将y视为因变量,x视为自变量,从而得到方程:y=ax+b其中, a 是斜率,表示自变量 x 对因变量 y 的影响程度;b 是截距,表示当 x = 0 时 y 的值
西瓜数据集”是机器学习入门中一个非常经典的分类数据集,常用于讲解和实现基本的分类算法。该数据集通过若干个特征来描述西瓜的外观和内部质量,并据此判断是否为“好瓜”。色泽(如:青绿、乌黑、浅白)根蒂(如:蜷缩、稍蜷、硬挺)敲声(如:浊响、沉闷、清脆)纹理(如:清晰、稍糊、模糊)脐部(如:凹陷、稍凹、平坦)触感(如:硬滑、软粘)密度(浮点数,如:0.697)含糖率(浮点数,如:0.460)好瓜(类别标签

降维是指将高维数据通过某种方式映射到低维空间的过程,同时尽量保留原数据中的关键信息。在机器学习和数据挖掘中,尤其是图像处理、文本分析、生物信息等领域中,数据往往具有成百上千的特征维度,这些高维特征不仅计算开销大,还容易引发所谓的“维度灾难简单来说,降维的目的就是——用更少的特征,表示尽可能多的原始信息。先读取人脸数据并打标签。用PCA手动降维,提取主成分。用KNN基于降维特征训练模型并预测。输出准
欠拟合(Underfitting):模型太“笨”,没学明白。过拟合(Overfitting):模型太“聪明”,把题都死记硬背了,结果考试不会用。模型在训练集上表现就不好,说明它没学到数据的规律,太简单了。模型在训练集上学得很好,但测试集上表现很差——它不是学懂了,而是背答案了!欠拟合——模型太蠢,学不懂过拟合——模型太聪,死记硬背解决欠拟合——换复杂模型,多训练解决过拟合——模型降智,加数据,做正
决策树(Decision Tree)是一种基本的分类与回归方法,在机器学习中被广泛应用,尤其适合处理结构化的、有明显规则逻辑的问题场景。它的核心思想是通过一系列“是/否”判断,不断将样本划分,直到最终落入一个明确的分类结果。比如选择好瓜的时候:我们可以认为色泽、根蒂、敲声是一个西瓜的三个特征,每次我们做出抉择都是基于这三个特征来把一个节点分成好几个新的节点。在上面的例子中,色泽、根蒂、声音特征选取
Anaconda 是一个开源的 Python 和 R 发行版,专注于数据科学、机器学习和科学计算。它集成了大量常用的数据科学工具和库(如 NumPy、Pandas、Matplotlib、Scikit-learn 等),并提供了一个强大的包管理工具 Conda,可以轻松创建、管理和切换不同的 Python 环境。