




- @qq_62000508
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文详细演示了Oracle数据库手工SQL注入的全过程。首先通过order by判断字段数,利用union select确定回显位置;接着获取数据库信息、表名和字段名;然后通过排除法枚举数据,克服Oracle的rownum限制;最后解密MD5密码登录获取Key。文中还解析了关键指令如global_name、user_tables等的应用场景,提供了Oracle环境下SQL注入的实用技术方案。
联邦学习中的个性化层方法:FedPer算法研究 摘要: 本文针对联邦学习中数据统计异质性导致的模型性能下降问题,提出了一种名为FedPer的新型联邦学习方法。该方法通过将深度神经网络划分为共享的基础层和设备特定的个性化层,有效解决了传统联邦平均算法在个性化任务中的局限性。基础层通过联邦平均进行协同训练,而个性化层则利用本地数据进行独立优化。实验结果表明,FedPer在非相同划分的CIFAR数据集和
简单来说,SAM 是一个通用的图像分割模型。图像分割(Image Segmentation):是计算机视觉中的一项核心任务,旨在识别图像中的哪些像素属于哪个对象。通俗点说,就是把图里的东西“抠”出来。Anything(任何事物):这是 SAM 最恐怖的地方。传统的分割模型通常只能识别训练过的特定物体(比如只认识猫、狗、车)。而 SAM 拥有**零样本(Zero-shot)**迁移能力,意味着它从未
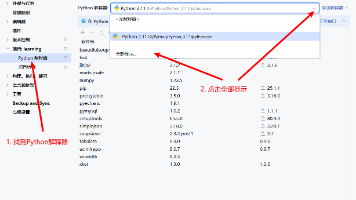
如何在PyCharm 2025.1.2中配置Conda解释器:打开PyCharm设置通过"+"添加本地解释器选择"Conda"类型定位到conda.bat脚本文件(路径参考:Anaconda/scripts/conda.bat)加载并选择已创建的Conda环境确认后等待包扫描完成即可使用配置好的Conda环境进行开发
本文很详细的介绍了如何在IntelliJ IDEA中使用内置的可视化工具创建和管理MySQL数据库。首先,确保已安装MySQL并创建或打开一个工程。接着,通过IDEA的“Database”功能连接到本地MySQL数据库,输入用户账号和密码进行测试连接。连接成功后,通过SQL语句创建一个测试数据库,并在其中创建数据表,定义表名、字段和约束。最后,演示了如何通过IDEA的console进行数据的增删改
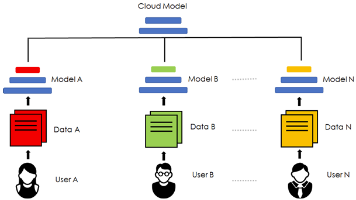
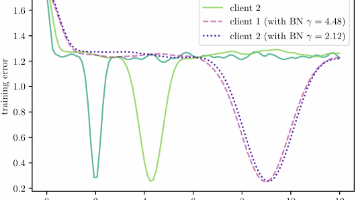
摘要 本文提出FedBN方法,通过局部批量归一化(Local Batch Normalization)解决联邦学习中特征偏移非独立同分布(feature shift non-iid)问题。与现有工作主要关注标签分布差异不同,该方法针对不同客户端特征分布的差异,如医学影像中不同扫描仪导致的图像差异。FedBN在模型平均时保持BN层参数本地化,其余层进行聚合。实验表明,FedBN在多个数据集上优于Fe
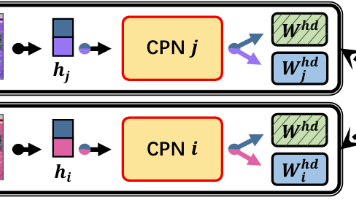
近期,个性化联邦学习(pFL)在隐私保护、协作学习以及解决客户端(例如医院、智能手机等)之间的统计异质性方面引起了越来越多的关注。大多数现有的pFL方法主要集中于在客户端级别的模型参数中利用全局信息和个性化信息,而忽略了数据才是这两种信息的来源。为了解决这个问题,我们提出了联邦条件策略(FedCP)方法,该方法为每个样本生成一个条件策略,以将其特征中的全局信息和个性化信息分离,然后分别通过全局头部
知识蒸馏:大模型智慧向小模型的高效迁移 知识蒸馏是一种将复杂大模型(教师模型)的知识迁移到轻量小模型(学生模型)的技术。其核心思想是利用教师模型输出的软标签(概率分布)而非硬标签,使学生模型学习到更丰富的类别间关系等"暗知识"。典型流程包含教师模型生成软标签、学生模型同时学习真实标签和软标签、通过特定损失函数优化三个关键环节。 该技术经历了从经典输出层蒸馏到特征蒸馏、多教师蒸馏
如何在PyCharm 2025.1.2中配置Conda解释器:打开PyCharm设置通过"+"添加本地解释器选择"Conda"类型定位到conda.bat脚本文件(路径参考:Anaconda/scripts/conda.bat)加载并选择已创建的Conda环境确认后等待包扫描完成即可使用配置好的Conda环境进行开发
传统联邦学习的策略演进反映了从“简单可行”到“高效实用”的持续探索。从最初的FedAvg到应对各种实际挑战的改进算法,从中心化架构到去中心化、分层化设计,联邦学习生态系统正在不断丰富和完善。理解这些传统策略不仅有助于我们在实际应用中选择合适方案,更为探索联邦学习的前沿方向——如个性化联邦学习、跨模态联邦学习、联邦大模型等——奠定了坚实基础。随着技术的成熟和生态的发展,联邦学习必将在保护数据隐私的前