




- @qq_54556560
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
人体姿态估计(Human Pose Estimation)是计算机视觉领域的核心任务之一,旨在从图像或视频中检测并定位人体的关键解剖部位(如关节、头部、四肢等),构建人体骨架模型。2D姿态估计:在图像平面上预测人体关键点的二维坐标。3D姿态估计:进一步恢复关键点的三维空间位置,或估计关节角度。多人姿态估计:在复杂场景中同时检测多人的姿态,解决遮挡、密集人群等问题。应用场景广泛,包括动作识别、人机交
由德国卡尔斯鲁厄理工学院与丰田研究院联合创建,是自动驾驶领域最经典的评测基准,涵盖立体视觉、光流、3D检测等任务。包含市区、乡村和高速公路场景的真实数据,标注对象包括车辆、行人等,支持多传感器数据(摄像头、激光雷达、GPS等)。

12、 元素的访问: 可以[-1]选择最后一个元素,可以用[1:3]选择第二个和第三个元素。7、常见的标准算术运算符(+、-、*、/ 和 **)都可以被升级为 按元素运算。10、对张量中的所有元素进行求和sum(),会产生一个只有一个元素的张量。5、改变一个张量的形状而不改变元素数量和元素值,可以调用。6、使用全0、全1、其他常量或者从特定分布中随机采样的数字。15、 转换为numpy张量、转换为
深度学习在人工智能领域持续取得进展,主要研究方向包括持续学习、多目标优化、IoT与边缘计算融合、模型架构创新、生成模型与多模态学习、可解释性与通用人工智能、跨学科应用与科学智能。持续学习通过域增量学习等方法解决灾难性遗忘问题;多目标优化通过动态权重分配等技术平衡冲突目标;IoT与边缘计算结合推动智慧城市等应用;模型架构创新如Transformer和轻量化网络提升性能与效率;生成模型与多模态学习在文
总结:在终端运行时,显示找不到某文件或程序(但是此文件就在当前执行程序的目录下,如上图中的mmdetection3d目录下),也可以在终端执行次命令,来设置临时环境变量,代表此临时环境变量为mmdetection3d目录下均是。

计算机视觉(CV)作为人工智能的重要分支,自20世纪50年代起经历了多个发展阶段。从早期的模式识别和三维场景理解,到70年代David Marr的视觉计算理论框架,再到2000年代深度学习的兴起,CV技术不断突破。2012年AlexNet在ImageNet竞赛中的成功标志着深度学习在CV中的主流化。如今,CV在工业、医疗、自动驾驶、零售和安防等多个领域广泛应用,市场规模持续扩大。尽管面临复杂场景适
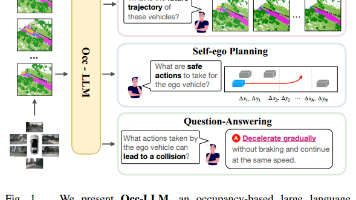
大型语言模型(LLMs)在机器人和自动驾驶领域取得了长足的进步。本研究提出了第一个基于占用的大型语言模型(Occ LLM),它代表了将LLM与重要表示相结合的开创性努力。为了有效地将占用率编码为LLM的输入,并解决与占用率相关的类别不平衡问题,我们提出了运动分离变分自编码器(MS-VAE)。这种创新方法利用先验知识在将动态对象输入到定制的变分自动编码器(VAE)之前将其与静态场景区分开来。这
核心应用场景环境维护:清理缓存、检查已安装库(避免冲突)。依赖管理:搜索和验证库版本(确保兼容性)。故障排查:解决安装失败或版本错误问题。

Softmax回归是一个多类分类模型使用Softmax操作子得到每个类的预测置信度使用交叉熵来衡量预测和标号的区别。
目标检测是计算机视觉的核心任务之一,旨在从图像或视频中定位并识别出所有感兴趣的物体,输出其类别和位置(通常以边界框表示)。其研究主要围绕精度与速度的平衡展开,并逐步向多模态、轻量化、开放集等方向扩展。Two-Stage检测算法(如R-CNN系列):首先生成候选区域(Region Proposal),再对候选区域分类和位置修正。这类算法精度高但速度较慢,典型代表包括Fast R-CNN、Faster