




- @qq_53129597
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:混淆矩阵是评估机器学习模型的核心工具,包含TP、TN、FP、FN四种判断结果。在安全领域(如入侵检测),正样本通常代表攻击流量,负样本为正常流量。混淆矩阵存在两种常见格式:理论标准格式(正例在前)和Python sklearn格式(负例在前)。关键指标如精确率(Precision)和召回率(Recall)存在权衡关系,安全场景更关注高召回率(减少漏报)。F1分数适合处理样本不平衡问题,而准确

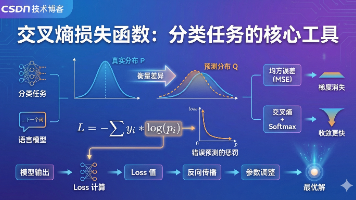
摘要:交叉熵损失函数是分类任务的核心工具,通过衡量预测分布与真实分布的差异来评估模型性能。其核心逻辑是利用对数函数特性,对错误预测施加更大惩罚。相比均方误差,交叉熵配合Softmax能避免梯度消失问题,错误越大则梯度越大,收敛更快。该函数在训练阶段处于关键位置,将模型表现量化为损失值,指导参数调整方向。在入侵检测等多分类任务及语言模型预测中具有重要作用,既实现最大似然估计,又保证优化过程的凸性,促
摘要:深度学习与强化学习在AI系统中扮演不同角色:前者负责感知与模式识别(如自动驾驶识别红灯),后者专注于决策优化(如决定刹车动作)。核心区别在于反馈机制(标准答案vs奖惩信号)和数据来源(静态历史数据vs动态交互数据)。深度学习提供基础认知能力,强化学习则实现长期收益最大化。二者通常协同工作,如ChatGPT先用深度学习学习语言,再通过强化学习优化回答策略。本质差异在于:深度学习是"认
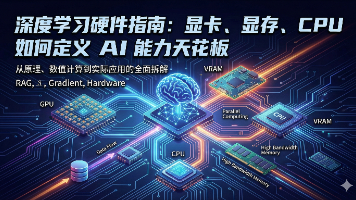
摘要:本文用"超级厨房"比喻解析AI硬件分工:CPU是统筹主厨,GPU是并行切菜团,显存则是关键灶台案板。以7B大模型为例,显存容量决定能否运行(门槛),GPU核心数影响速度(TFLOPS),CPU处理数据供给(防短板),而显存带宽(如HBM)对大规模训练尤为关键。完整流程展示了数据从CPU预处理到GPU计算的流转过程,指出硬件配置需平衡各环节,避免因显存不足或CPU瓶颈导致G
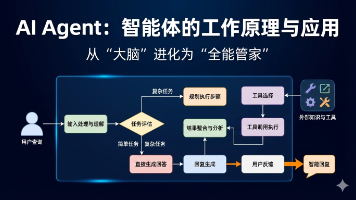
文章摘要: AIAgent(智能体)实现了从"缸中之脑"到"全能管家"的进化,为LLM配备了感知、工具和规划能力。其核心采用"双轨制"逻辑:先评估任务复杂度,再分流执行简单对话或复杂任务。对于复杂任务,Agent能自主拆解目标、调用工具并整合结果,具备自我纠错能力。这种架构如同操作系统,将LLM的推理能力转化为实际执行力,突破了数字与物理
摘要:深度学习与强化学习在AI系统中扮演不同角色:前者负责感知与模式识别(如自动驾驶识别红灯),后者专注于决策优化(如决定刹车动作)。核心区别在于反馈机制(标准答案vs奖惩信号)和数据来源(静态历史数据vs动态交互数据)。深度学习提供基础认知能力,强化学习则实现长期收益最大化。二者通常协同工作,如ChatGPT先用深度学习学习语言,再通过强化学习优化回答策略。本质差异在于:深度学习是"认
DeepSeek的MLA(多头潜在注意力)机制通过创新性的压缩存储方式大幅降低显存占用。与传统MHA(多头注意力)需要存储完整的K/V值不同,MLA将输入压缩为2个数的"压缩包"存储,利用矩阵结合律实现计算时无需还原原始数据。这种设计将显存占用降至MHA的1/4,同时保持相近性能表现。在初始化方面,预训练阶段采用标准初始化保证模型学习能力,而微调阶段则采用LoRA的特殊初始化策

摘要:深度学习与强化学习在AI系统中扮演不同角色:前者负责感知与模式识别(如自动驾驶识别红灯),后者专注于决策优化(如决定刹车动作)。核心区别在于反馈机制(标准答案vs奖惩信号)和数据来源(静态历史数据vs动态交互数据)。深度学习提供基础认知能力,强化学习则实现长期收益最大化。二者通常协同工作,如ChatGPT先用深度学习学习语言,再通过强化学习优化回答策略。本质差异在于:深度学习是"认
ToC与ToB业务的核心差异解析 摘要:ToC和ToB是两种截然不同的商业模式。ToC直接面向个人消费者,注重用户体验和情感驱动,典型如微信、抖音等,特点是决策快、用户量大、体验至上。ToB则服务于企业机构,强调理性价值和投资回报,如企业微信、阿里云等,具有决策链长、客户价值高、产品功能优先等特点。两者在用户角色、决策方式、产品设计、营销策略等方面存在本质差异:ToC追求爆款和流量转化,ToB看重

未来的两个风口?论如何将大模型与车联网结合!
