




- @qq_51399582
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
ECBS(Enhanced CBS)是CBS算法的有界次优改进版本。通过双层Focal Search与动态下界传递,在解代价增加不超过w倍的前提下,搜索效率可提升一个数量级以上。本文从GCBS→BCBS→ECBS演进路线出发,拆解高层约束树FOCAL选择与低层Focal Search机制,给出伪代码与Python实现,并通过实验对比验证加速效果,适用于大规模仓储AGV、无人机编队等MAPF场景。

Inflated M* 是 M* 算法的有界次优改进版本。通过子维度展开(Subdimensional Expansion),只有在机器人路径发生冲突时才合并其规划空间,配合加权 A* 的膨胀启发式,在保证 w-次优界的前提下将搜索速度提升 5~15 倍。本文从联合配置空间困境出发,详解碰撞集演化、策略缓存与回溯机制,给出完整伪代码与 Python 实现,并与 CBS/ECBS 横向对比,适用于稀

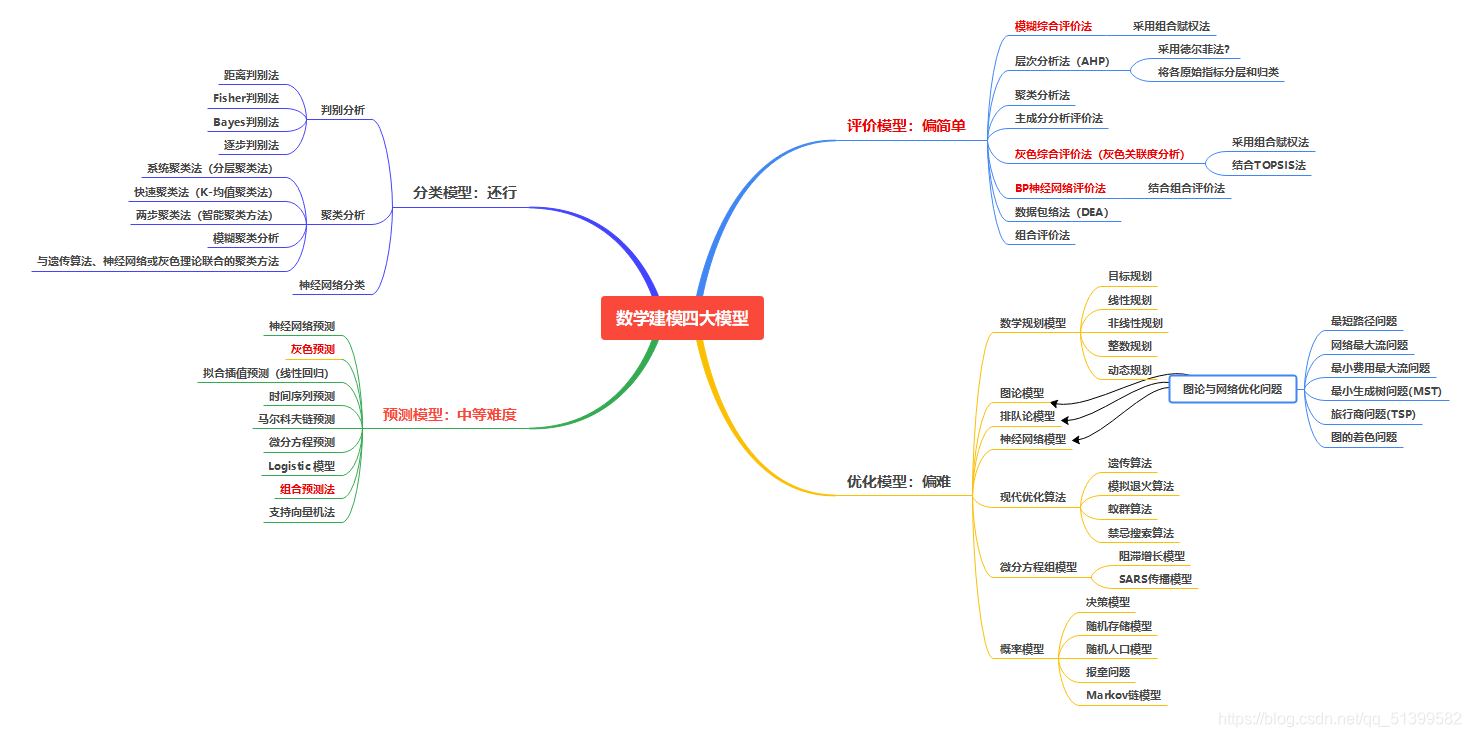
目前数学建模国赛培训已经进入火热的备战时期,许多高校早已开始了数学建模的线上培训。而且因为疫情的原因,数学建模国赛是线上不受影响,但一些线下的大型比赛被推迟,如电子设计竞赛国赛等,小编就是因为这样转战数模国赛,专心投入数学建模的国赛备战中。小编在这里总结一下数学建模常用的四大模型(评价模型、预测模型、优化模型、分类模型)并且分享一下历年的国赛题目以及优秀的国赛论文。目录1.数学建模四大模型:2.历
人工智能已经存在于我们生活中很久了。但对很多人来讲,人工智能还是一个较为“高深”的技术,然而再高深的技术,也是从基础原理开始的。人工智能领域中就流传着10大算法,它们的原理浅显,很早就被发现、应用,甚至你在中学时就学过,在生活中也都极为常见。
1.【MADRL】多智能体深度强化学习《纲要》2.【MADRL】独立Q学习(IQL)算法3.【MADRL】基于MADRL的单调价值函数分解(QMIX)算法4.【MADRL】多智能体深度确定性策略梯度(MADDPG)算法5.【MADRL】多智能体双延迟深度确定性策略梯度(MATD3)算法6.【MADRL】多智能体近似策略优化(MAPPO)算法7.【MADRL】反事实多智能体策略梯度(COMA)算法

【RL】强化学习入门:从基础到应用强化学习,本文介绍了强化学习的基础和python经典实现。(Reinforcement Learning, RL)是机器学习的一个重要分支,它使得智能体通过与环境的互动来学习如何选择最优动作,以最大化累积奖励。近年来,随着深度学习技术的发展,强化学习取得了显著的进展,尤其在复杂任务中的表现令人瞩目。

MADDPG (Multi-Agent Deep Deterministic Policy Gradient) 是一种用于多智能体强化学习环境的算法。它由2017年发布的论文《Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments》提出。MADDPG结合了深度确定性策略梯度(DDPG)算法的思想,并对多智能体场

随机网络蒸馏(RND)是一种自监督学习方法,旨在提高强化学习中的探索效率。该算法由 Chesney et al. 在论文《Random Network Distillation as a Method for Intrinsic Motivation》提出,RND 利用随机神经网络的输出与环境状态的真实特征之间的差异来生成内在奖励,鼓励智能体探索未见过的状态。这种方法尤其适用于外部奖励稀疏的环境。

Plan2Explore是自监督强化学习中的一项创新算法,旨在解决探索问题,尤其是在没有外部奖励信号或奖励稀疏的情境下,如何让智能体有效探索环境。Plan2Explore通过自监督的方式来提高智能体对环境的探索能力,不依赖外部奖励。

为了进一步提升Curiosity-driven Exploration (CDE)算法在强化学习任务中的性能,可以考虑通过以下几个方面的改进来优化智能体的探索行为和效率.
