- @qq_45981086
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
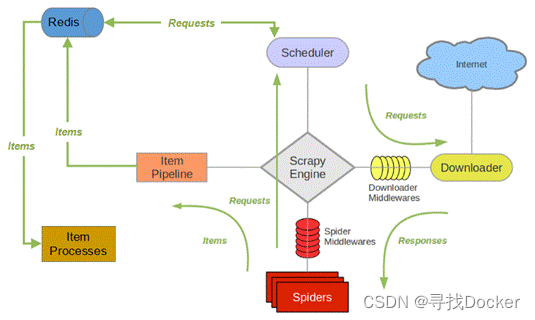
与scrapy框架不同的是,scrapy-redis框架中request链接不再交付于调度器(Scheduler)中url队列,而是保存在redis数据库中,再由过滤器进行过滤,符合要求的请求链接再交付于调度器(Scheduler),此外redis数据还可以存储到本地数据库(item processes)。从(2) 开始重复,直到调度器中没有更多的Request为止。(4) 当调度条件满足时,调度
回归任务是指对变量进行预测的任务。

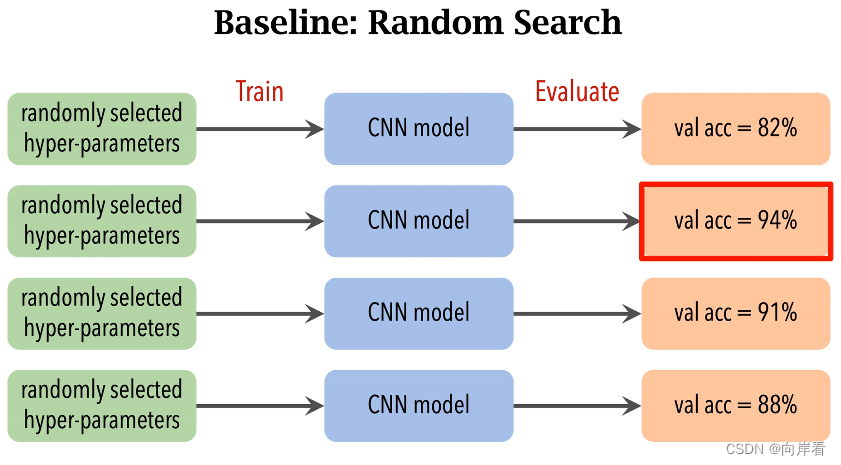
在神经网络中有一些需要手动设置的超参数,主要包括两类,一类是Architecture(神经网络结构),比如有多少卷积层,每层有多少卷积核,卷积核有多大。另一类是Algorithm(优化算法),如SGD优化算法。这两类超参数都可以影响到训练过程中的参数进而影响到测试集上的准确率。 因此如何自动调整超参数是一门很热门的研究方向。
Kaggle房价预测。

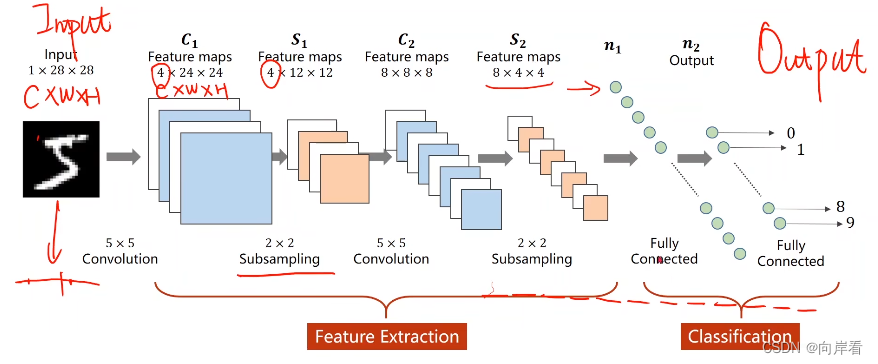
全连接神经网络:完全由线性层串行连接起来的网络。在全连接神经网络中,我们会把图像像素映射为一个较长的张量,这样会丧失图像像素之间原始的空间结构。会保留图像像素之间原始的空间结构的神经网络。convolution卷积:会保留图像像素之间原始的空间结构。subsampling下采样:缩小图像,提取特征值。卷积神经网络分为特征提取和分类两部分。Input Channel输入通道数、Output Chan
Mybatis-plus + 通用mapper(tk.mybatis)

回归任务是指对变量进行预测的任务。
经过了多层感知机后,相当于将原始的特征转化成了新的特征,或者说提炼出更合适的特征,这就是隐藏层的作用。

在神经网络中有一些需要手动设置的超参数,主要包括两类,一类是Architecture(神经网络结构),比如有多少卷积层,每层有多少卷积核,卷积核有多大。另一类是Algorithm(优化算法),如SGD优化算法。这两类超参数都可以影响到训练过程中的参数进而影响到测试集上的准确率。 因此如何自动调整超参数是一门很热门的研究方向。
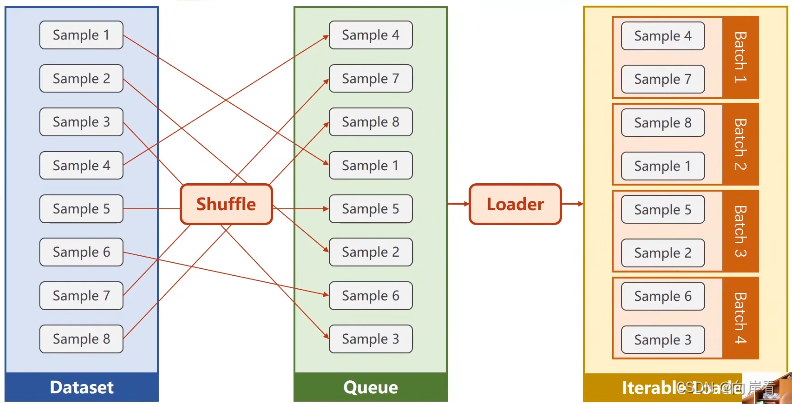
处理数据集两种方法:1.数据集不够大,直接读进内存。2.数据集所占空间比较大,像图片、语音的数据集,将文件名读进内存,根据文件名加载问价。只要数据集能支持索引和提供数据集长度,DataLoader就能对数据集生产batch。名词解释:Epoch,Batch,Batch-Size,Iterations。Batch-Size(批量大小):batch进行一次前向和反向传播的样本数量。shuffle:是否