




- @qq_45932996
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
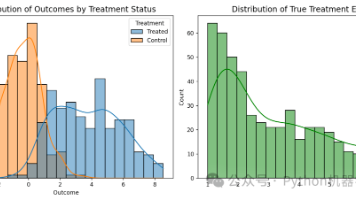
DeepIV(Deep Instrumental Variables)是一种用于的计量经济学和机器学习方法。它的核心目标是在存在**内生性(Endogeneity)**问题时,估计处理(Treatment)对结果(Outcome)的因果效应。在标准的回归分析(如 OLS)中,我们假设处理变量 T 与模型的误差项 ε 不相关 (Cov(T, ε) = 0)。存在一些未观测到的混淆因子(Unobser
本研究基于肺癌调查数据集,通过机器学习方法构建了肺癌预测模型。研究流程包括数据预处理、探索性分析、特征工程和模型构建与评估。研究实现了逻辑回归、朴素贝叶斯、支持向量机、随机森林、K近邻、XGBoost和深度神经网络7种模型,其中K近邻模型表现最佳,准确率达92.86%。通过可视化分析揭示了年龄、性别分布特征及吸烟、饮酒等风险因素与肺癌的关联。研究还采用ROC曲线、混淆矩阵、PR曲线等多种评估方法,
本研究基于肺癌调查数据集,通过机器学习方法构建了肺癌预测模型。研究流程包括数据预处理、探索性分析、特征工程和模型构建与评估。研究实现了逻辑回归、朴素贝叶斯、支持向量机、随机森林、K近邻、XGBoost和深度神经网络7种模型,其中K近邻模型表现最佳,准确率达92.86%。通过可视化分析揭示了年龄、性别分布特征及吸烟、饮酒等风险因素与肺癌的关联。研究还采用ROC曲线、混淆矩阵、PR曲线等多种评估方法,
线性回归算法作为经典的机器学习算法之一,拥有极为广泛的应用范围,深受业界人士的青睐。该算法主要用于研究分析响应变量如何受到特征变量的线性影响。其通过构建回归方程,借助各特征变量对响应变量进行拟合,并且能够利用回归方程进行预测。鉴于线性回归算法较为基础、简单,所以比较容易入门。线性回归算法是一种较为基础的机器学习算法,基于特征(自变量、解释变量、因子、协变量)和响应变量(因变量、被解释变量)之间存在
本研究构建了一个集成自动化机器学习全流程系统,涵盖数据预处理、模型优化、验证解释及部署应用。通过SMOTE平衡处理、Optuna超参数优化和集成学习(Voting/Stacking)构建高性能模型,并采用DCA决策曲线、校准曲线和SHAP/LIME进行深度验证与解释。系统实现了从数据清洗(包括异常值处理、特征筛选)到16种算法的全面评估(ROC曲线、AUC森林图等十多项指标),最终基于Stream
线性回归算法作为经典的机器学习算法之一,拥有极为广泛的应用范围,深受业界人士的青睐。该算法主要用于研究分析响应变量如何受到特征变量的线性影响。其通过构建回归方程,借助各特征变量对响应变量进行拟合,并且能够利用回归方程进行预测。鉴于线性回归算法较为基础、简单,所以比较容易入门。线性回归算法是一种较为基础的机器学习算法,基于特征(自变量、解释变量、因子、协变量)和响应变量(因变量、被解释变量)之间存在
接下来,通过切片操作从 shap_values 中提取出每个类别的 SHAP 值,分别存储shap_values_class_1,shap_values_class_2 和 shap_values_class_3 中。为后续的工作准备好所需的工具,我们需要引入如 numpy 、pandas 用于数据处理,xgboost 用于模型构建,用于模型解释的shap,用于可视化的seaborn和matplo
