




- @qq_44681809
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
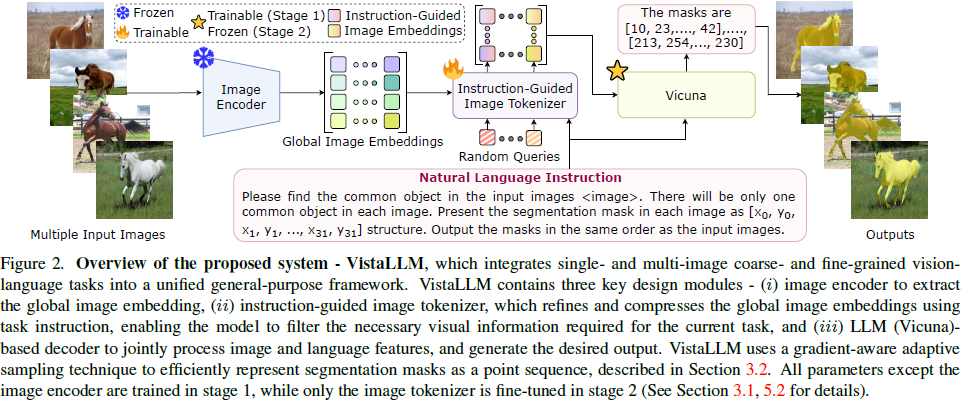
本文提出 VistaLLM,一个通用视觉系统,能够在单图像和多图像输入的情况下,同时处理 粗粒度和细粒度的视觉-语言任务。该模型利用指令引导的图像编码器和梯度感知自适应采样技术来优化输入处理,并使用新构建的数据集(CoinIt) 进行训练
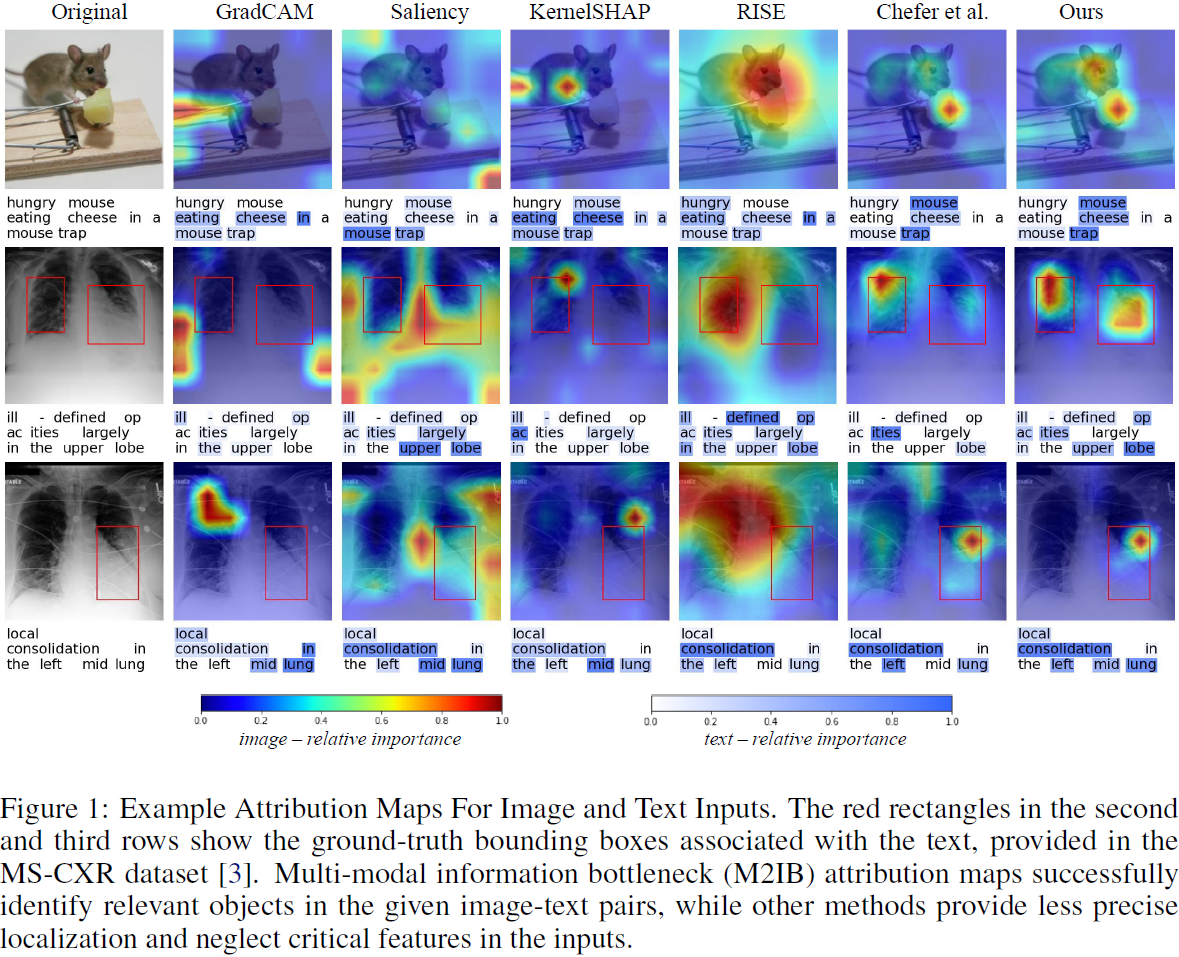
为提高视觉语言模型的可解释性,本文提出多模态信息瓶颈,该方法学习潜在表示,压缩无关信息同时保留相关的视觉和文本特征。与通常使用的单模态归因方法不同,M2IB 不需要地面真实标签。
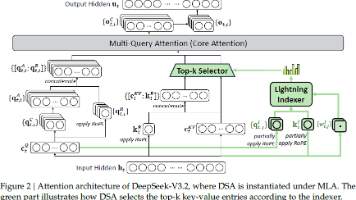
本研究提出 DeepSeek-V3.2,使用 DSA 降低注意力复杂度,同时在长上下文场景保持性能;通过改进的 GRPO 机制使大规模 RL 训练稳定可扩展;使用大规模合成智能体任务生成复杂任务,使模型在真实工具链任务中具备强鲁棒性与泛化性
GPT-5.2 专注于企业级生产系统与多工具 Agent 工作流,在专业知识处理、编程、科学推理等任务上表现显著提升。GPT-5.2改进了结构化思维、指令遵循和工具调用能力,同时降低冗余和幻觉风险。

目录0. 前言1. MOOCs2. 机器学习库和框架3. 书籍4. 云服务5. 证书6. 深度学习7. 移动和边缘设备8. 编程语言9. 结论10. 参考0. 前言我们并不会惊讶于这样一个事实:ML行业一直在改变,因为众所周知,人工智能在以创新的速度前进着我的观点是,大多数ML从业者在2020年使用的的技术,在2021年来看,可能是过时的。因此,我们需要进行适应和改变在这篇文章中,我将给出现如今可
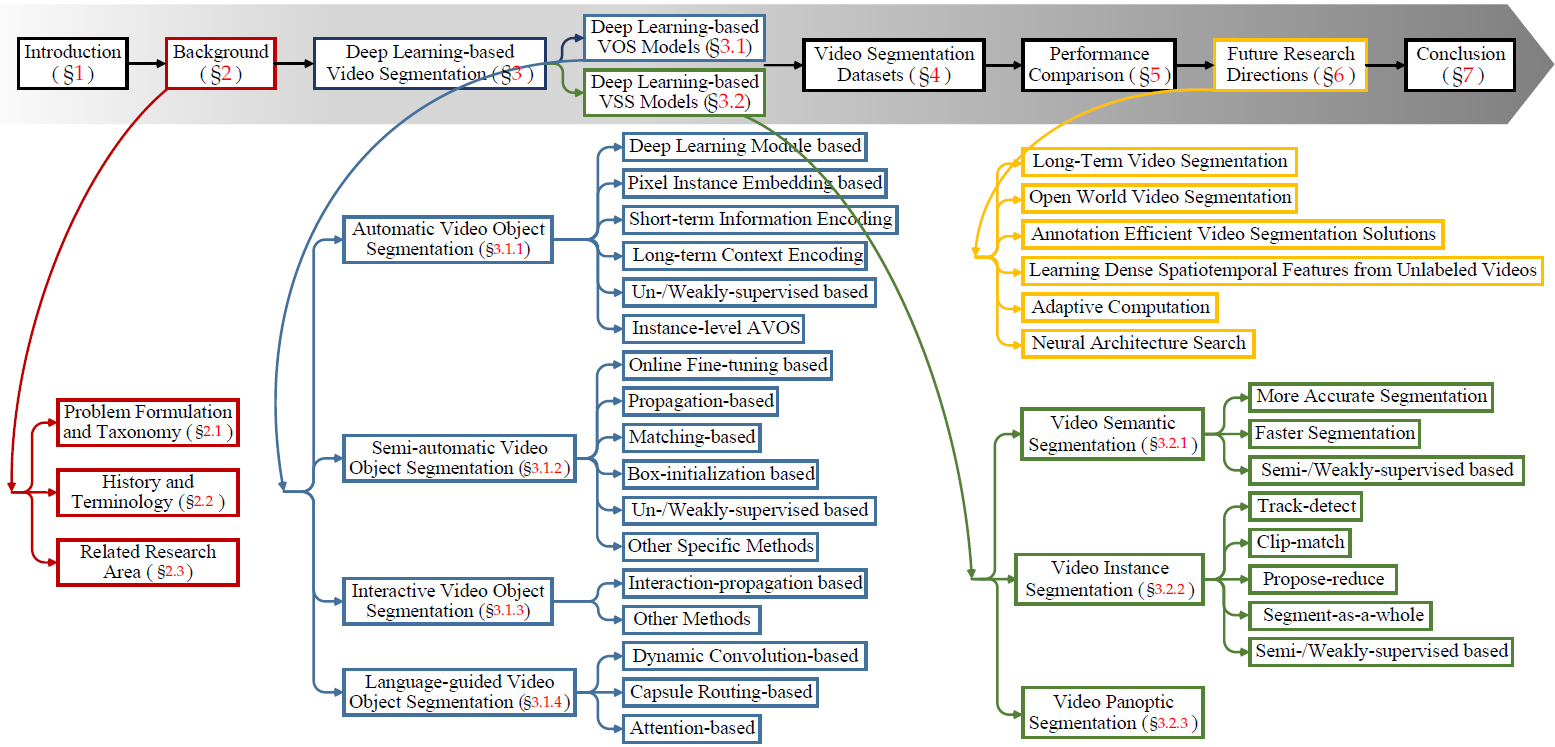
本文回顾视频分割的两条基本研究路线:视频目标分割(object segmentation)和视频语义分割(semantic segmentation)。本文介绍它们各自的task setting、背景概念、感知需求、发展历史以及主要挑战。本文详细概述相关的方法和数据集的代表性文献。本文在一些知名的数据集上对这些方法检测(benchmark)。最后,指出这些领域的opne issue以及未来的研究方
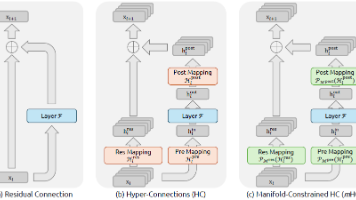
虽然超连接提出的扩宽残差流宽度和多样化连接能带来性能增益,但这些连接的无约束性质会导致信号发散。这种破坏损害了跨层信号能量的守恒,引发训练不稳定性并阻碍深度网络的可扩展性。为解决这些挑战,本文引入了流形约束超连接,一个将残差连接空间投影到特定流形上的通用框架。
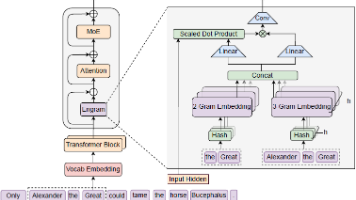
本文介绍条件记忆作为对主流条件计算范式的互补稀疏性维度,旨在解决通过动态计算模拟知识检索的低效问题。本文通过 Engram 模块实例化了这一概念。通过构建稀疏性分配问题,本文发现了一个 U 形缩放定律,证明了稀疏容量在 MoE 专家和 Engram 记忆之间的混合分配严格优于纯 MoE 基线。在此定律指导下,本文将 Engram 扩展到 270 亿参数,在多个领域实现了卓越性能。
本文介绍了 ViT³ 和 T⁵ 两篇关于 ViT 测试时训练的研究成果。ViT³ 系统性地探索了视觉 TTT 的设计空间,提出了六条核心原则,基于此构建的ViT³模型在多项视觉任务中表现优异。T⁵ 则聚焦如何将预训练 Softmax Transformer 快速转化为线性TTT模型,提出结构对齐和表示对齐策略,通过权重继承和键实例归一化实现高效转换。
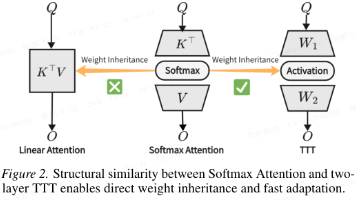
通过使隐藏状态成为一个机器学习模型,并将更新规则设为自监督学习的一步,本文将监督学习表述为学习如何学习,包含两个嵌套循环。外循环与常规训练相同。外循环的参数是内循环的超参数。由于隐藏状态在测试序列上也会进行训练更新,这些层被称为TTT层
