




- @qq_44625774
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
目录下载与安装下载安装配置nodejs相关配置npm相关配置nodejs的基本使用搭建简易后端服务器npm的基本使用搭建vue 2.0开发环境下载与安装下载点击_Node.js中文网_根据自身系统进行下载即可安装点击下载的安装包进行安装选择安装的路径位置下一步、没有特殊要求默认即可该选项建议勾选,一些npm的包需要这些环境配置最后点击install完成安装配置nodejs相关配置简介:Node.j
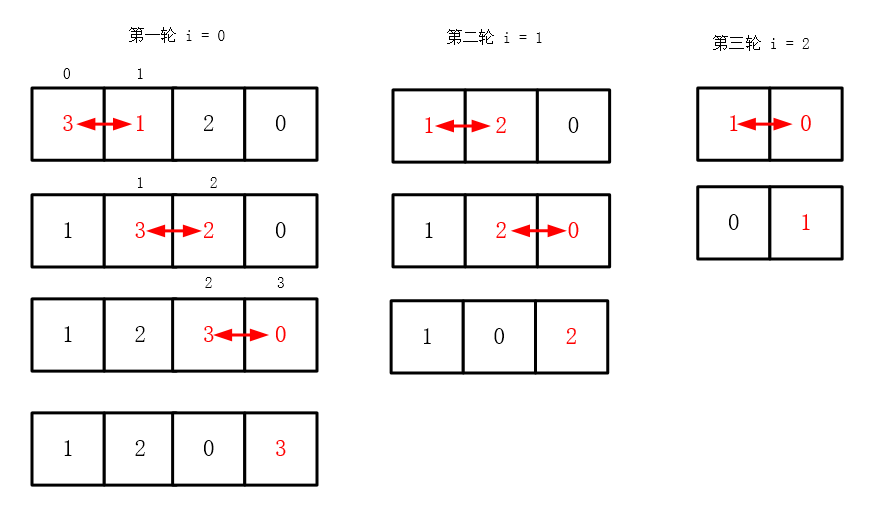
这里写目录标题冒泡排序1.排序原理2.源代码详细排序全过程演示3.算法改进源代码4.最终改进冒泡排序1.排序原理冒泡排序就是通过比较一个序列中相邻的两个数据大小,并交换位置来对数据进行排序的排序方法2.源代码#include<stdio.h>#define N 10int main(){int i,j,temp;int num[N]={9,8,7,6,5,4............
系统:ubuntu24.04架构:x86。
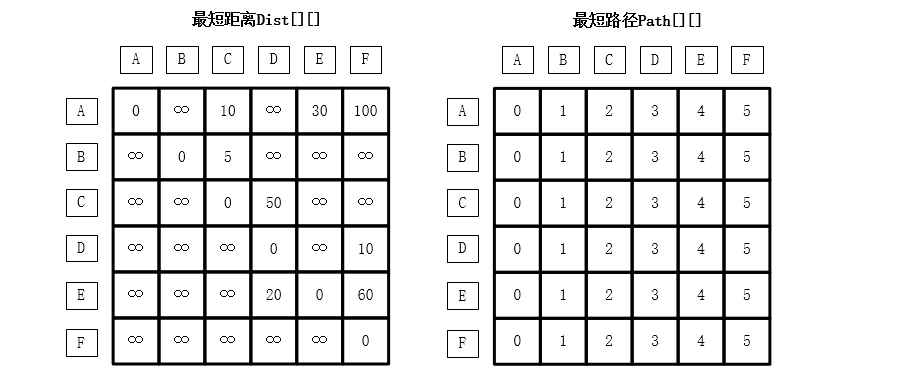
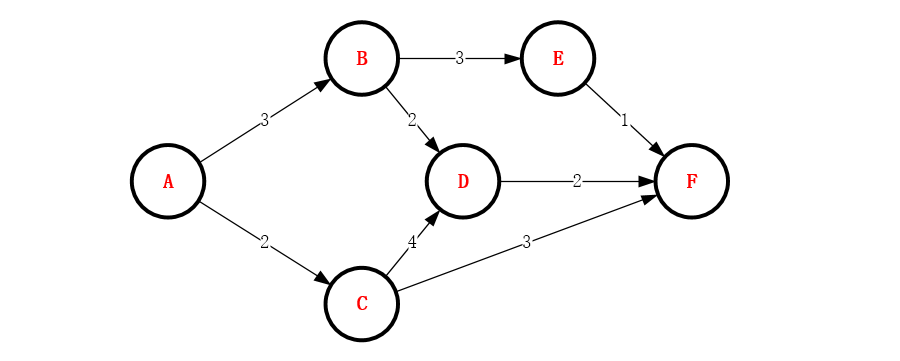
最短路径Floyd算法
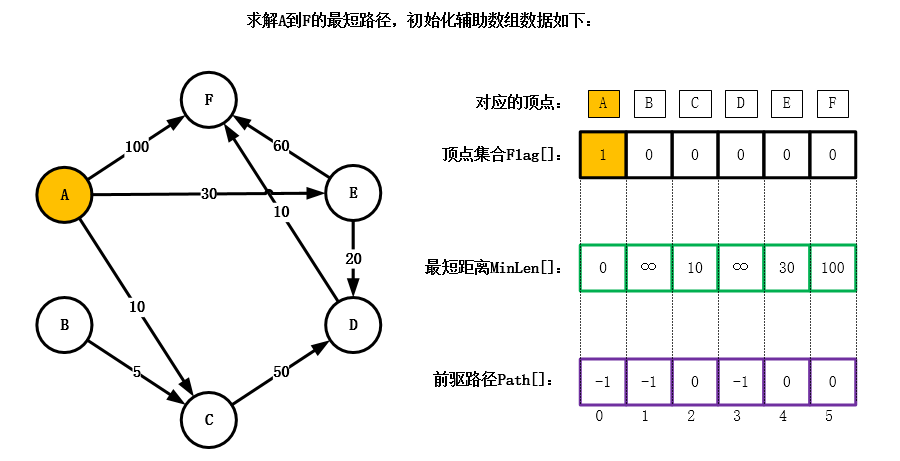
图的应用单源最短路径迪杰斯特拉(Dijkstra)算法2. 源代码:3. 测试:测试环境 : Windows 10编译软件 : Visual C++ 6.0测试用例:
在图结构中,源点到终点的所有路径中,其中具有最大路径长度的路径称为关键路径。
哈希表中元素是由哈希函数确定的,将数据元素的关键字key作为自变量,通过一定的函数关系(称为哈希函数),计算出的值,即为该元素的存储地址。
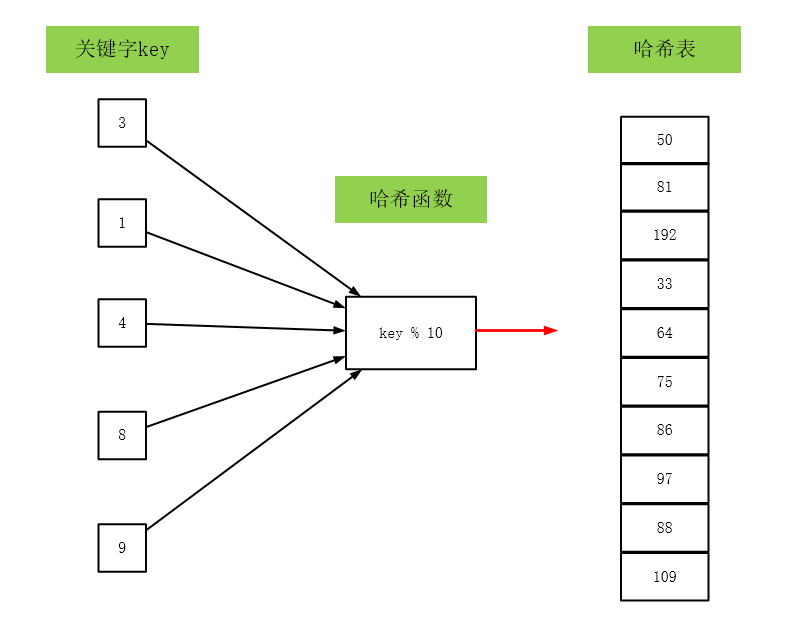
这玩意害我浪费了半天时间,要换新的就不能把旧的删掉,恼。

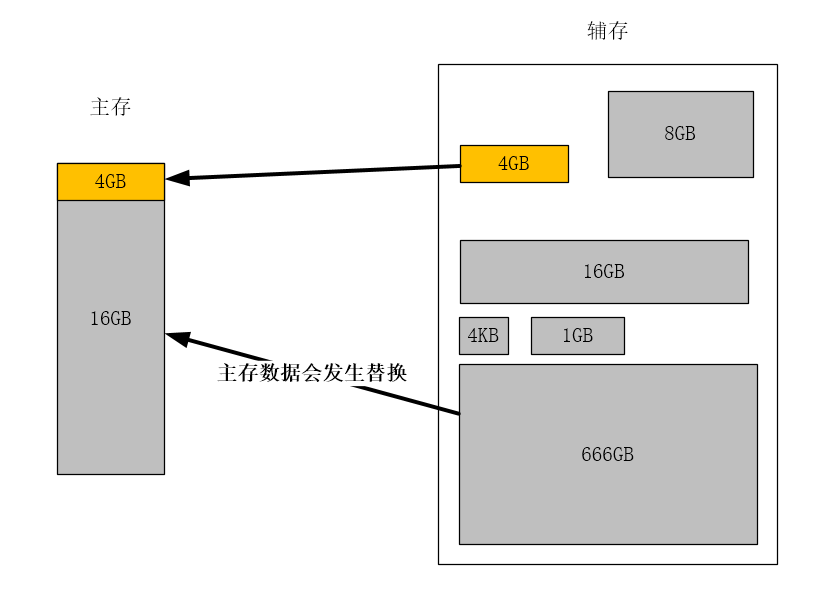
同时,如果一个程序的大小超过了主存的大小,主存内的数据就会发生替换,使得主存的空间看起来很大,这也就是其虚拟的特性原理。其原理和Cache相同,利用局部性原理,将频繁查找到的页表记录存储在查询速度更快的快表中,减少访问主存的次数。在进行分页后,我们能充分的利用主存中的零碎空间将程序A装入主存,但我们接下来该如何读取程序A呢?在建立好页表后,我们就可以根据逻辑地址来读取程序A的数据在主存中的实际位置
系统:ubuntu24.04架构:x86。