- @qq_44193969
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
方法输出格式: XML输出示例# 技能以下技能扩展了你的能力。要使用技能,请使用 read_file 工具读取其 SKILL.md 文件。available="false" 的技能需要先安装依赖项——你可以尝试使用 apt/brew 安装。
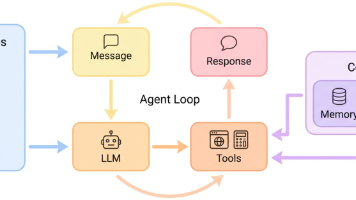
Deep Agents:开箱即用的AI Agent框架 Deep Agents是一个功能强大的AI Agent框架,提供开箱即用的解决方案,帮助开发者快速构建智能助手。该框架支持任务规划、文件系统访问、Shell执行、子Agent管理等高级功能,并通过简洁的API简化开发流程。核心组件包括SDK、命令行工具和评估套件,采用模块化设计支持扩展。开发者只需几行代码即可创建具备复杂任务处理能力的AI A
顶级 (90%+): ByteRover > MemMachine ≈ Mastra > Hindsight (Gemini-3) ≈ Honcho ≈ Backboard*准顶级 (85-90%): Hindsight (OSS-120B) ≈ Supermemory (Gemini-3 / GPT-5)
文章摘要:本文介绍了大语言模型(LLM)存在的两个关键限制——无状态性和上下文窗口有限性,以及传统RAG式记忆解决方案的不足。作者提出MemMachine记忆系统,通过模拟人类认知分层(工作记忆、情景记忆、语义记忆)来解决这些问题。系统架构包含客户端层、API层、核心服务层和存储层,采用模块化设计支持多租户隔离和模型替换。关键创新点包括事件记忆流处理、结构化语义抽取和向量图存储技术,最终实现细粒度

摘要:Tree of Thoughts (ToT)是一种新型的大语言模型推理框架,通过构建解决方案树实现多步推理。论文以Game24游戏为例,展示了ToT如何通过生成-评估-选择的三步循环进行智能搜索:首先生成多个候选操作(如1+1=2),然后评估每个候选的前景(sure/likely/impossible),最后选择最优路径继续探索。相比传统方法,ToT能同时考虑多种可能性,支持回溯修正,显著提
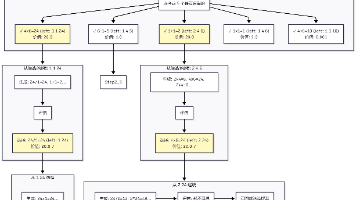
文章摘要:本文介绍了大语言模型(LLM)存在的两个关键限制——无状态性和上下文窗口有限性,以及传统RAG式记忆解决方案的不足。作者提出MemMachine记忆系统,通过模拟人类认知分层(工作记忆、情景记忆、语义记忆)来解决这些问题。系统架构包含客户端层、API层、核心服务层和存储层,采用模块化设计支持多租户隔离和模型替换。关键创新点包括事件记忆流处理、结构化语义抽取和向量图存储技术,最终实现细粒度
文章摘要:本文介绍了大语言模型(LLM)存在的两个关键限制——无状态性和上下文窗口有限性,以及传统RAG式记忆解决方案的不足。作者提出MemMachine记忆系统,通过模拟人类认知分层(工作记忆、情景记忆、语义记忆)来解决这些问题。系统架构包含客户端层、API层、核心服务层和存储层,采用模块化设计支持多租户隔离和模型替换。关键创新点包括事件记忆流处理、结构化语义抽取和向量图存储技术,最终实现细粒度
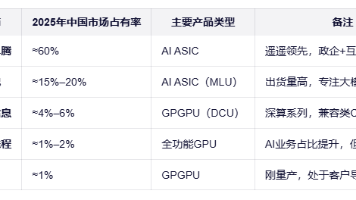
随着人工智能和大模型技术的快速发展,GPU算力需求持续增长。在国际形势变化和供应链安全的背景下,国产GPU/DCU成为重要的战略选择。本报告对当前市场上主流的国产AI加速卡进行全面调研,从硬件规格、软件生态、性价比等维度进行分析评估,为采购决策提供参考依据。昇腾毋庸置疑是国产卡第一首选,本文主要叙述除昇腾外的其它国产显卡。当前国产GPU/DCU市场格局初步形成,但整体生态仍在建设中。寒武纪和海光D
想象一下这样的场景:你有一个 AI 助手,它可以在你常用的所有通讯工具上与你对话——WhatsApp、Telegram、Discord、Slack、iMessage……它不仅能聊天,还能帮你执行命令、操作浏览器、读写文件、管理日程,甚至控制你的电脑。这一切都发生在你自己的设备上,而不是某个远程服务器。这,就是OpenClaw。让 AI 在你已有的通讯渠道上为你工作,同时保持数据本地化、隐私可控。O

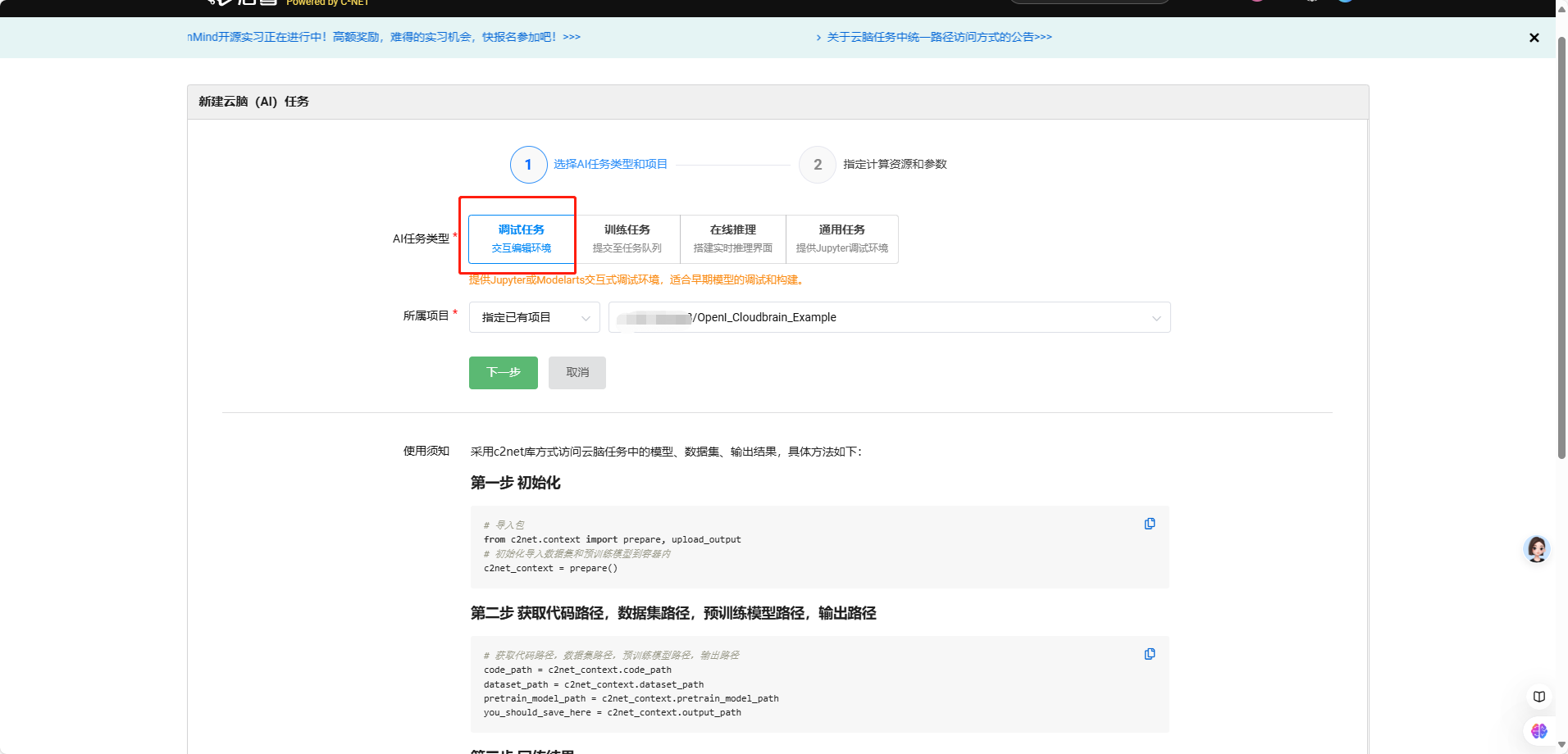
前段时间想玩玩昇腾,发现华为云上租地GPU服务器,没有最新地cann8.0的镜像,自己折腾了许久,根本无法替换自己的镜像上去,此处省略一万字关于华为云的吐槽。启智社区提供了不少国产厂家的免费算力,接下来,话不多说,开整。