




- @qq_43854103
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
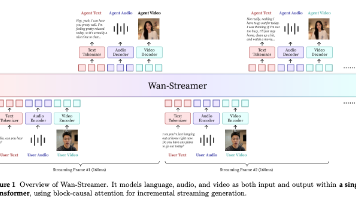
作者为了解决现有AI数字人反应慢、像“机器人”的问题,提出了一个名为的原生流式模型,它能在一个里同时处理音视频的输入输出,实现了约550毫秒的超低延迟全双工交互。这篇论文最大的贡献是证明了用一个统一的模型就能搞定实时的音视频交互,不再需要繁琐的模块拼接。目前的局限是生成的视频分辨率还较低(192p),但这为未来开发真正“活”的数字人指明了方向,值得精读其架构设计思路。
作者为了解决VLA模型泛化能力差、需要大量演示数据的问题,提出了一个名为Agentic-VLA的在线自适应框架,通过让模型在交互中自我进化和利用过往经验,在LIBERO基准测试中将长程任务成功率提升了12.3%,并将收敛速度提高了2.4倍。这篇论文最大的贡献是证明了通过引入“智能教练”机制(动态奖励、语言引导、经验记忆),可以让VLA模型具备像人一样的持续学习能力。虽然目前主要在仿真环境中验证,且
Google DeepMind团队构建了基于Veo视频基础模型的生成式评估系统,用于在名义场景、分布外(OOD)场景及安全测试中评估双臂机器人的Gemini Robotics策略,并通过1600+次真实世界实验,验证该系统能准确预测策略相对性能、OOD下性能退化及安全漏洞。
逆动力学就是解决这个问题的方法。:与逆动力学相反,正向动力学则是当你知道作用在机器人上的力(例如电机提供的扭矩)时,预测机器人将会如何移动的过程。也就是说,给定机器人的当前状态(如位置和速度)以及施加于其上的力,正向动力学能够告诉我们接下来会发生什么,机器人将怎样改变它的位置或速度。在机器人学中,“inverse dynamics”(逆动力学)和 “forward dynamics”(正向动力学)

只用了很少的真机训练数据(7.5k条),通过“P图”扩充数据和“预测动作片段”而非单步动作,训练出了一个能听懂人话、在没见过的厨房场景里也能完成多种复杂任务的通用机器人。
只用了很少的真机训练数据(7.5k条),通过“P图”扩充数据和“预测动作片段”而非单步动作,训练出了一个能听懂人话、在没见过的厨房场景里也能完成多种复杂任务的通用机器人。
本文提出了一种名为 RoboFactory 的框架和基准测试,利用大模型生成“逻辑、空间、时间”三重限制条件,来自动化地生成高质量的多机器人协作训练数据,并探索了如何训练多机器人模仿学习模型。

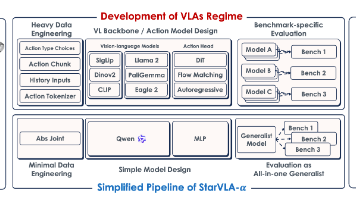
用一个强VLM backbone(Qwen3-VL) + 轻量MLP action head + 最小化数据处理,构建了一个简洁但强性能的VLA基线,系统验证了"很多复杂设计其实没必要"。
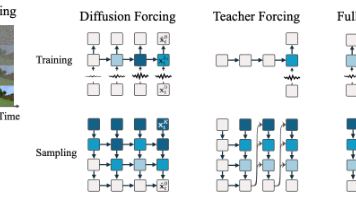
本文提出了一种叫“扩散强制(Diffusion Forcing)”的新方法,让模型既能像GPT一样自由地生成长短不一的序列(如视频、动作),又能像全序列扩散模型一样进行全局规划和纠错,解决了长序列生成容易“崩”掉的问题。
本文提出了一个名为“Great March 100 (GM-100)”的机器人学习评测基准,包含100个精心设计的、涵盖长尾行为的任务,旨在解决现有评测任务过于单一、无法全面评估机器人智能水平的问题。