
写文章




- @qq_43797487
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
python报错Ran out of input
报错显示:首先进行Traceback,发现报错语句为:pickle.load()之后网上查找原因有:(1)https://www.cnblogs.com/rychh/p/9833318.html(2)https://blog.csdn.net/qq_20373723/article/details/85258535对上面作者提供的方法进行测试:import picklewith open("./d
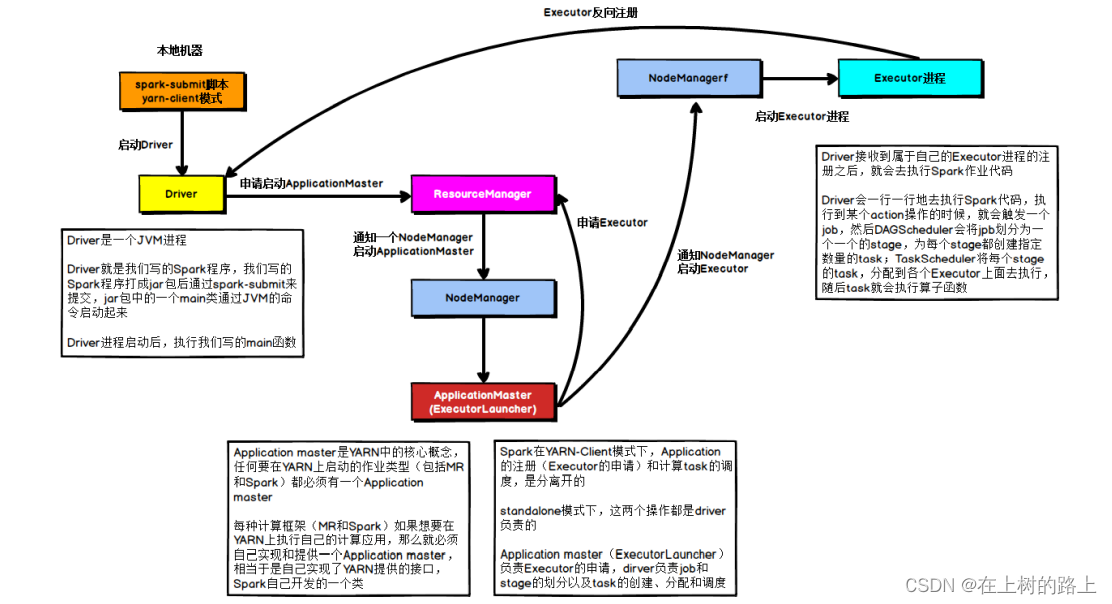
Spark核心概念(一)
分布式资源:Yarn,Standalone、K8s等资源容器1)将多台机器的物理资源:CPU、内存、磁盘从逻辑上合并为一个整体实现统一的资源管理使用Yarn进行资源管理。因为Yarn作为统一的资源管理平台,不论是MR,Spark还是Flink都能在上面运行,而类似Standalone的资源管理平台只能在Spark上运行,不具备统一性。所以使用Yarn作为统一的资源管理平台能够降低开销成本2.Spa
Kafka的分区规则(轮询分区、黏性分区)/ 生产者实现生产数据的负载均衡
Kafka中生产数据的分区规则是什么?Kafka生产者怎么实现生产数据的负载均衡?为什么生产数据的方式不同,分区规则就不一样?1. 先判断是否指定了分区2. 如果指定了,就写入指定的分区3. 再判断是否指定了Key4. 如果指定了Key,按照Key的mur取余分区个数来决定5. 如果没有指定Key,按照黏性分区轮询分区

到底了