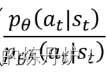- @qq_43703185
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
原文链接:https://blog.csdn.net/weixin_40519315/article/details/104408388UNet论文: 地址UNet源代码: 地址&nbs...
原文链接:https://www.jianshu.com/p/d4534ac94a65微信搜索:AI算法与图像处理,最新干货全都有大家好,今天给大家分享一篇人脸算法领域非常知名的paper,RetinaFace(RetinaFace: Single-stage Dense Face Localisation in the Wild)。同时也在文末附上开源项目的链接。跟着我一起读这篇论文,希望论文的
原文链接:https://blog.csdn.net/qq_41760767/article/details/97521397?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task...
原文链接:https://zhuanlan.zhihu.com/p/146309991EXPLORATION BY RANDOM NETWORK DISTILLATIONRND这类文章是基于强化学习在解决Atari游戏中蒙德祖玛的复仇的困境提出的。由于在这类游戏中存在非常稀疏的奖励,Agent在探索利用上存在很大的问题。RND也是第一个使用与人类平等的RL算法在蒙特祖玛的复仇上获得人类水平成绩的算
原文链接:https://blog.csdn.net/sinat_37422398/article/details/113085165\quad</span><span class="katex-html"><span class
原文链接:https://zhuanlan.zhihu.com/p/58053501Go-Explore是uber团队开发的算法,直观的意思是走到最好的状态(Go),然后从这个状态开始探索(Explore)。原文传送门Ecoffet, Adrien, et al. "Go-Explore: a New Approach for Hard-Exploration Problems." arXiv p
原文链接:https://blog.csdn.net/qq_35946628/article/details/90642257?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162736575416780261967321%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%2
【李宏毅讲了reward很稀疏的情况,但是在实际中,可能问题还会更进一步:很多场景是很难有一个明确的reward甚至没有reward。所以需要很厉害的agent或者直接由人来示范的资料,让agent跟着做。本文会讲两个。
原文链接:https://blog.csdn.net/ACL_lihan/article/details/103989581补充:问题:PPO2的损失函数,也就是奖励的平均值函数是怎么通过约束重要性权重让θ和θk的输出分布不至于差距很大的?也就是让其不至于差太多,导致off-policy失效理解:当A>0时候,根据损失函数(奖励函数平均值),此时会提高pθ(s,a)的概率,所以设置上限,不让pθ(