




- @qq_43426908
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
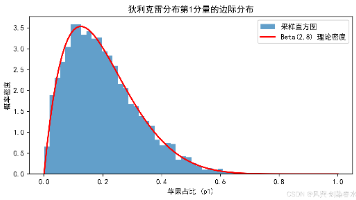
狄利克雷分布可以通俗地理解为:它是用来描述“把一个整体分成多个部分,每个部分占多少比例”这种分配情况的分布。你可以把它看作是“分布的概率分布”。
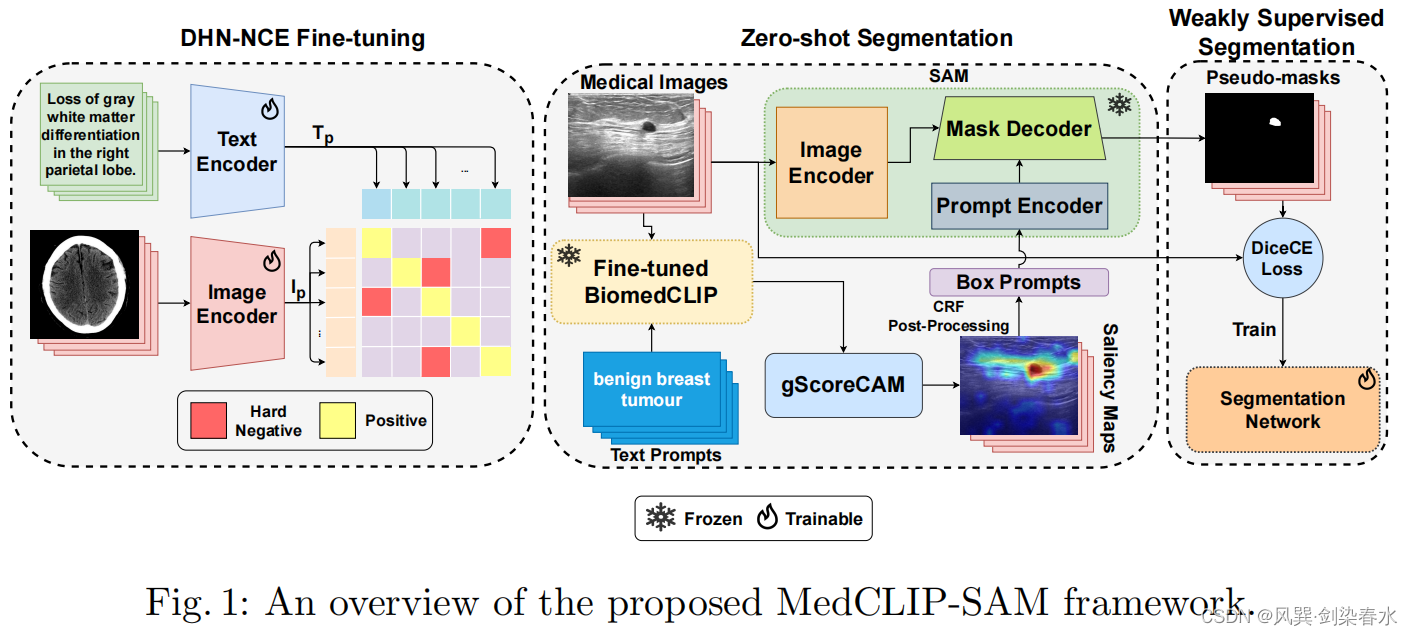
MedCLIP-SAM:一种通用医学图像分割新框架,将 CLIP 和 SAM 基础模型相结合,以获得基于文本提示的通用医学图像分割,并提出 DHN-NCE 新损失函数,性能表现出色~
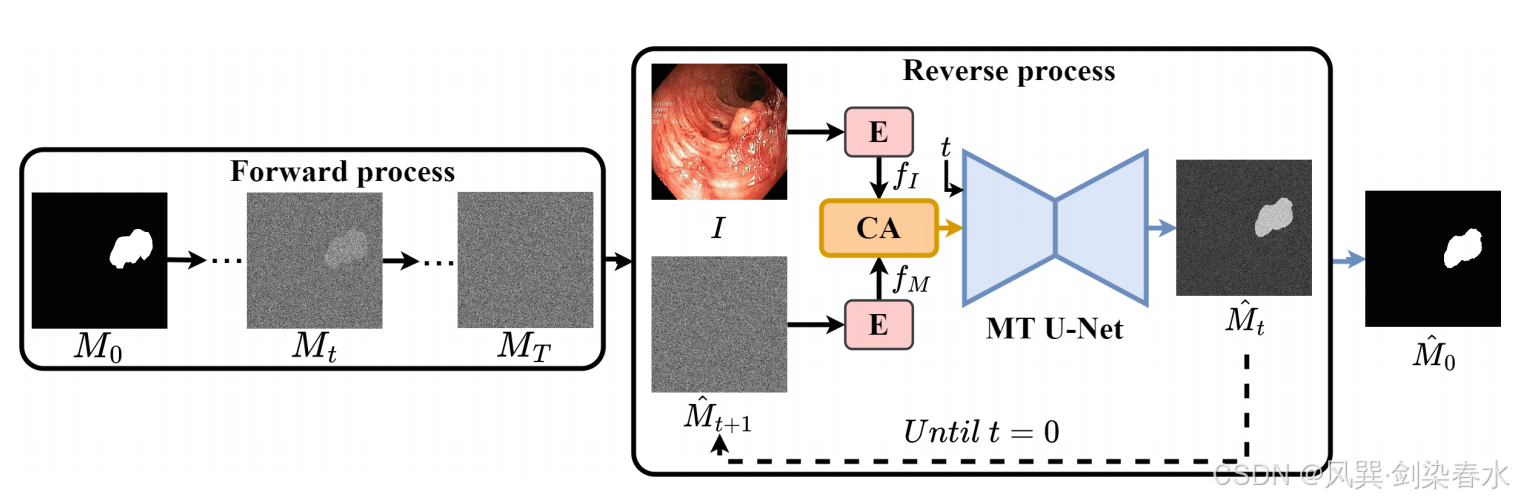
扩散模型在各种生成任务中展现了其强大的能力。然而,在医学图像分割中应用扩散模型时,仍需克服几个障碍:(1)扩散过程中条件化所需的语义特征与噪声嵌入不能很好地对齐;(2)扩散模型中使用的U-Net主干对反向扩散过程中准确像素级分割所必需的上下文信息不敏感。为了克服这些局限性,本文提出了一个交叉注意力模块来增强来自源图像的条件,并提出了一个基于 Transformer 的 U-Net,具有多尺寸窗口,
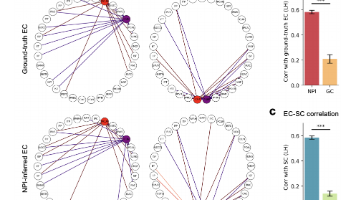
本文提出神经扰动推断(NPI)框架,通过构建人工神经网络作为大脑的替代模型,系统性扰动虚拟脑区并观测响应,实现全脑有效连接的无创绘制。NPI不仅能推断连接方向与强度,还可区分兴奋/抑制特性。在生成模型验证中,NPI优于传统方法(格兰杰因果、动态因果建模)。应用于静息态fMRI数据时,NPI揭示的结构支持的有效连接模式与皮层诱发电位实测数据高度一致。该研究为从相关分析转向因果理解大脑功能提供了新工具
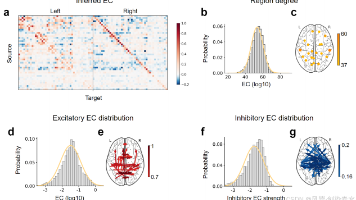
本文提出神经扰动推断(NPI)框架,通过构建人工神经网络作为大脑的替代模型,系统性扰动虚拟脑区并观测响应,实现全脑有效连接的无创绘制。NPI不仅能推断连接方向与强度,还可区分兴奋/抑制特性。在生成模型验证中,NPI优于传统方法(格兰杰因果、动态因果建模)。应用于静息态fMRI数据时,NPI揭示的结构支持的有效连接模式与皮层诱发电位实测数据高度一致。该研究为从相关分析转向因果理解大脑功能提供了新工具
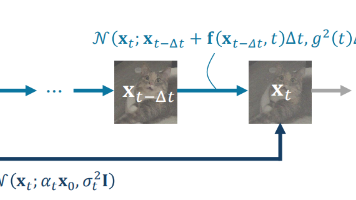
《扩散模型原理:从起源到发展》:第四章 扩散模型的今天:Score SDE 框架
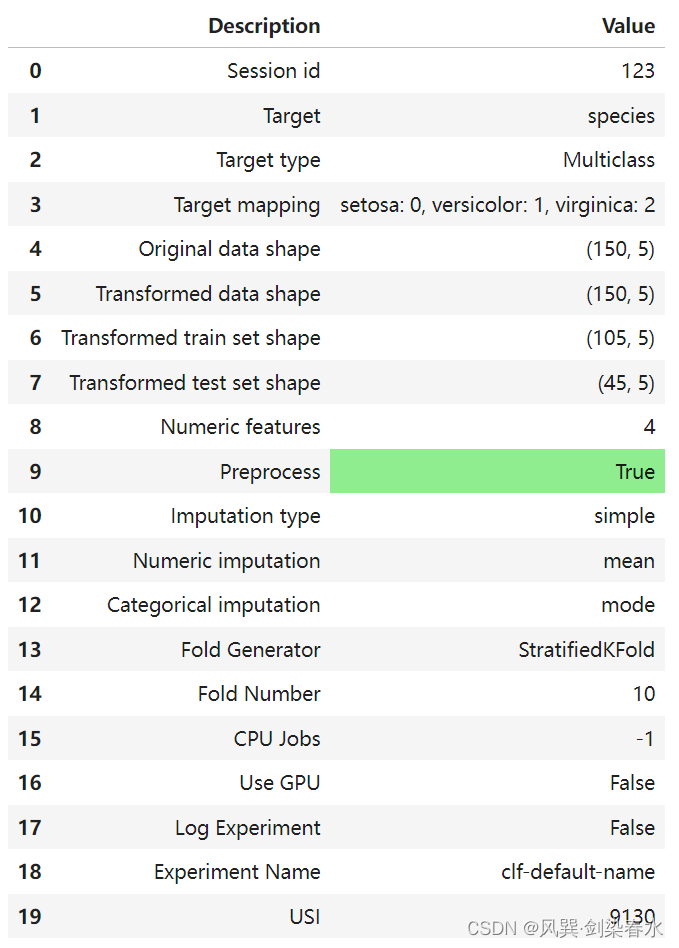
PyCaret是一个开源的、不用写很多代码的Python机器学习库,可以自动化机器学习工作流程,是一个端到端的机器学习和模型管理工具,可以成倍地加快实验周期,提高工作效率。PyCaret本质上是几个机器学习库和框架的封装,比如scikit-learn、XGBoost、LightGBM、CatBoost、spaCy、Optuna、Hyperopt、Ray等等。
《扩散模型原理:从起源到发展》:第四章 扩散模型的今天:Score SDE 框架
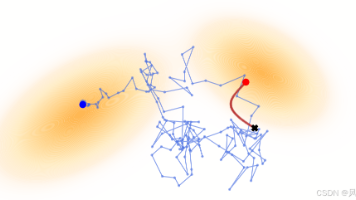
本文提出医学世界模型(MeWM),首次将世界模型应用于临床决策支持。MeWM由策略模型和动态模型组成:策略模型基于视觉-语言模型生成个性化治疗方案;动态模型通过肿瘤生成模型模拟不同治疗条件下的疾病演变。创新性地引入逆向动态模型,将仿真结果转化为生存分析指标,实现治疗方案优化。实验表明,MeWM在肿瘤影像合成真实性上表现优异,并能使TACE治疗方案选择的F1分数提升13%,展现了AI在精准医疗中的巨
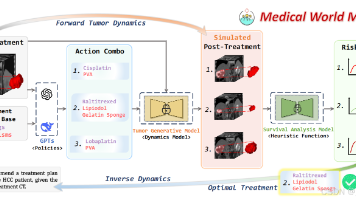
本文提出医学世界模型(MeWM),首次将世界模型应用于临床决策支持。MeWM由策略模型和动态模型组成:策略模型基于视觉-语言模型生成个性化治疗方案;动态模型通过肿瘤生成模型模拟不同治疗条件下的疾病演变。创新性地引入逆向动态模型,将仿真结果转化为生存分析指标,实现治疗方案优化。实验表明,MeWM在肿瘤影像合成真实性上表现优异,并能使TACE治疗方案选择的F1分数提升13%,展现了AI在精准医疗中的巨