- @qq_42103091
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
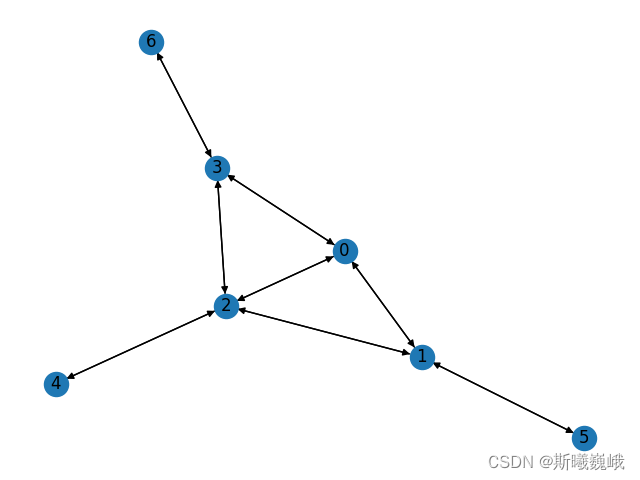
Ego graph指距离中心节点小于特定距离(特定路径长度)的所有结点构成的图,特定距离通常为1,即与中心节点直接有边连接。例如,假设下图左为一个完整的图,图右为以DDD为中心节点的ego-graph。有的也称为Ego Network。Ego graph中的中心被称为ego(DDD),而其它与ego连接的节点被称为alter(A,B,C,E,FA,B,C,E,FA,B,C,E,F)。在ego图中,

一.对数几率回归的定义1.1 广义线性模型在之前的机器学习(一):深入解析线性回归模型一文中所介绍的线性模型都是基于y=wTx+by=w^Tx+by=wTx+b这种形式的。但对于某些数据集虽然其自变量xxx与因变量yyy并不满足一元函数关系,但是可以通过某些函数g(.)g(.)g(.)让输入空间xxx到输出空间yyy的非线性函数映射转换成输入空间xxx到输出空间g(y)g(y)g(y)的线性函数映
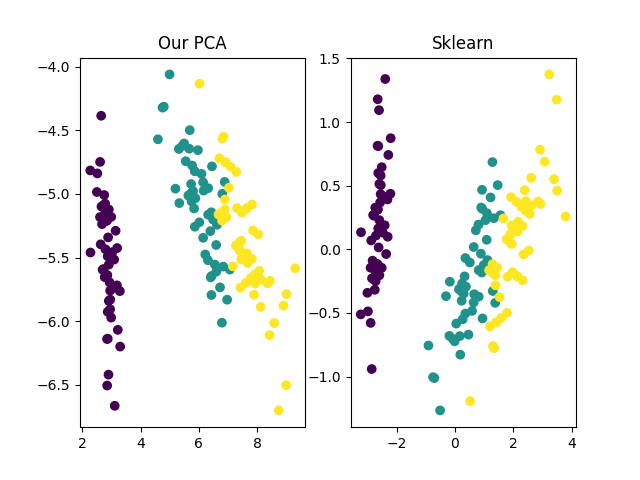
一.前言PCA可以说是业界使用的非常频繁的机器学习方法了,今天博主带领大家深入浅出PCA模型,相信看完本文你会对PCA有一个更加深刻的理解。话不多说,请看下文!!!二.理论介绍2.1 什么是PCAPCA的英文全称是Principal ComponentAnalysis,即主成分分析,它是一种常用的数据降维方法。数据降维指的是将高维空间中的数据在低维空间中进行表示,同时尽可能较少信息损失。通过数据降
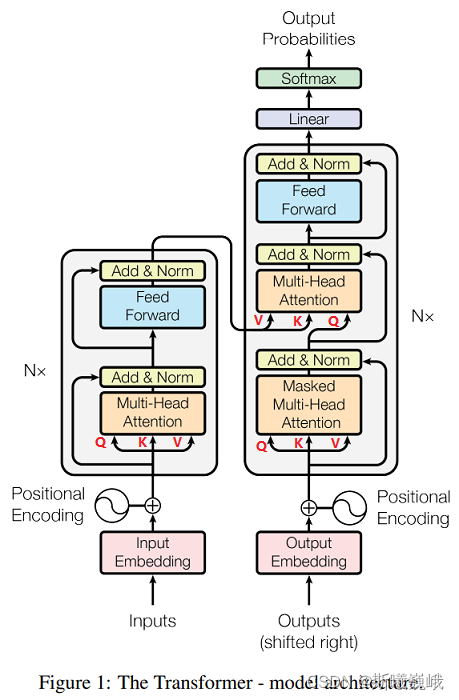
如今大火的大模型背后许多都离不开Transformer,本文将带你深入了解Transformer的架构。
一.前言2022年的第一篇博客,《机器学习》这个专栏去年由于自己的时间原因,更新的不勤,乘最近稍微有点时间准备开始陆陆续续更新,今天先来一道开胃菜:带拉普拉斯修正的朴素贝叶斯,话不多说请看下文。二.贝叶斯定理在正式介绍朴素贝叶斯算法之前先介绍下与其息息相关的贝叶斯定理(参考维基百科),其数学形式如下所示:P(A∣B)=P(A)P(B∣A)P(B)P(A|B) = \frac{P(A)P(B|A)}
一.为什么要安装tensorflow-gpu?本人之前使用的是cpu版本的,但是最近由于在做一个深度学习的项目,无奈cpu版本的运行速度实在是令我受不了了,因此我决定转向gpu版本(之前不装gpu版本是因为嫌麻烦)。在成功安装后,我有点后悔为什么不早点更换,因为速度提升的不是一星半点。因此,在这里我想向大家介绍如何安装gpu版本的tensorflow,话不多说,请看下文。二.安装过程2.1 ...
一.对数几率回归的定义1.1 广义线性模型在之前的机器学习(一):深入解析线性回归模型一文中所介绍的线性模型都是基于y=wTx+by=w^Tx+by=wTx+b这种形式的。但对于某些数据集虽然其自变量xxx与因变量yyy并不满足一元函数关系,但是可以通过某些函数g(.)g(.)g(.)让输入空间xxx到输出空间yyy的非线性函数映射转换成输入空间xxx到输出空间g(y)g(y)g(y)的线性函数映
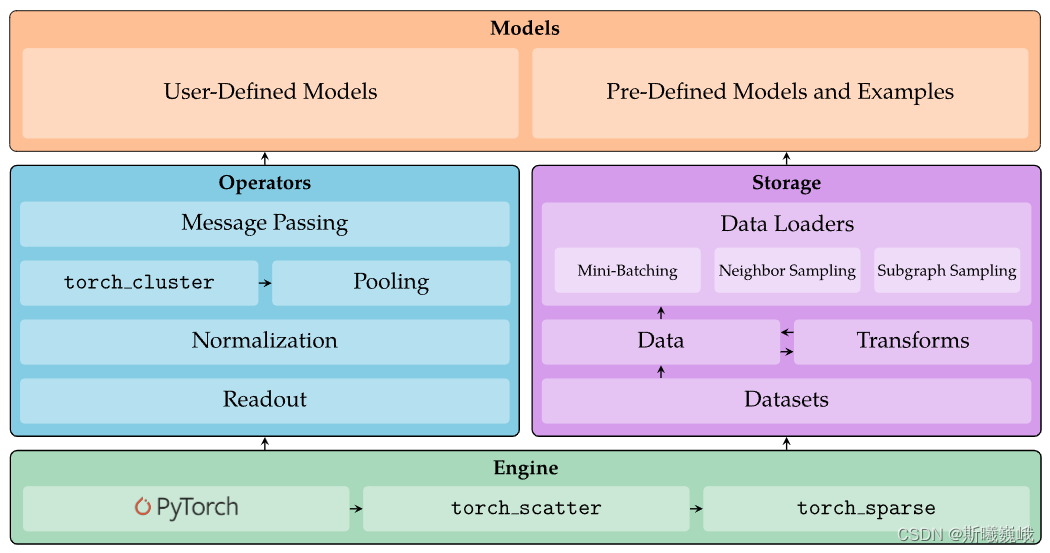
在PyG中,除了直接使用它自带的benchmark数据集外,用户还可以自定义数据集,其方式与Pytorch类似,需要继承数据集类。PyG中提供了两个数据集抽象类:下面是对其的详细介绍。
在Pytorch Geometric中我们经常使用消息传递范式来自定义GNN模型,但是这种方法存在着一些缺陷:在邻域聚合过程中,物化x_i和x_j可能会占用大量的内存(尤其是在大图上)。然而,并不是所有的GNN都需要表达成这种消息传递的范式形式,一些GNN是可以直接表达为稀疏矩阵乘法形式的。在1.6.0版本之后,PyG官方正式引入对稀疏矩阵乘法GNN更有力的支持(torch-sparse中的Spa
PyG全称是Pytorch Geometric,它是一个基于Pytorch构建的库,可以帮助用户快速构建和训练自己的图神经网络模型。PyG中实现了很多先进(state of the art)的GNN模块,例如、、、、等等。此外,PyG中还包含了大量的benchmark图数据集、丰富的图数据操作方法、支持多GPU。关于PyG的安装,推荐使用命令的方式:其中和分别表示Pytorch版本和CUDA版本的