




- @qq_41858402
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
clickhouse 分布式查询降级为本地查询问题排查

Hadoop 的诞生改变了企业对数据的存储、处理和分析的过程,加速了大数据的发展,受到广泛的应用,给整个行业带来了变革意义的改变;随着云计算时代的到来, 存算分离的架构受到青睐,企业开开始对 Hadoop 的架构进行改造。
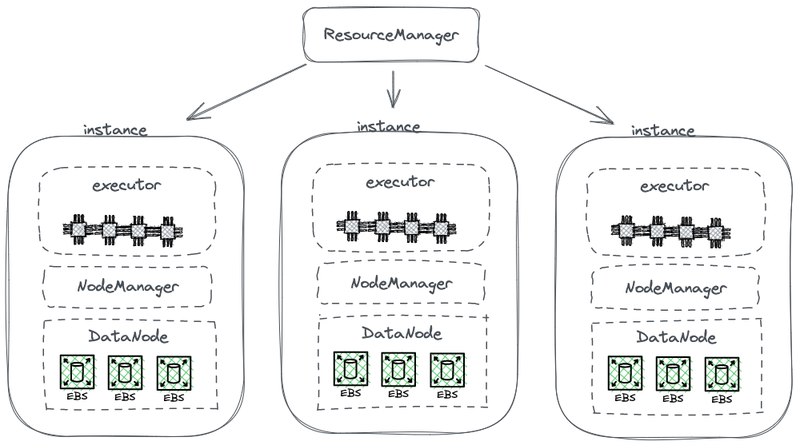
🎉🎉基于docker一站式hadoop集群管理,使用rust构建hdd客户端管理容器全生命周期
这篇文章介绍了解决在终端中全局代理不生效的方法。作者在使用实时流式SQL平台时遇到了下载速度极慢的问题,尽管他的Mac上开启了全局代理。他发现终端使用的网络配置与系统的全局代理设置是分开的,因此需要在终端中单独配置代理。作者给出了将代理配置封装成alias的方法,方便控制终端是否使用全局代理。经过配置后,他再次尝试下载时速度明显提升。
hadoop原来可以以这么简单的方式学习核心原理
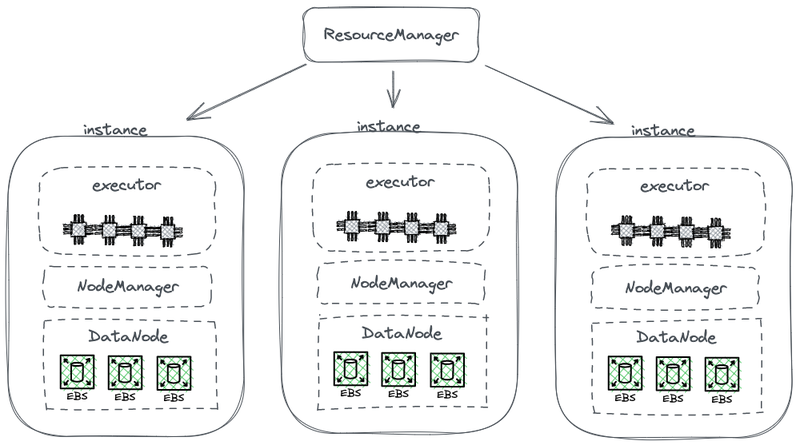
Hadoop 的诞生改变了企业对数据的存储、处理和分析的过程,加速了大数据的发展,受到广泛的应用,给整个行业带来了变革意义的改变;随着云计算时代的到来, 存算分离的架构受到青睐,企业开开始对 Hadoop 的架构进行改造。
作者:wjun平台:MacOS版本:Kafka 2.4.1 、Zookeeper 3.6.2一、Zookeeper 配置 SASL若只关注 kafka 的安全认证,不需要配置 Zookeeper 的 SASL,但 kafka 会在 zk 中存储一些必要的信息,因此 zk 的安全认证也会影响到 kafka ????????????1.1 新建 zoo_jaas.conf 文件zoo_jaas.con
