




- @qq_41776136
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1.最简单的重装现有的nvidia驱动2.用nvidia-smi查看显卡的工作模式,是不是变为了独占模式,用nvidia-smi -g 0 -c 0恢复默认模式。3.有可能是现有驱动的问题,可以尝试将驱动降级。这种方式适用于,在检查显卡驱动,cuda等都正常工作的时候使用。...
但是只开交互式绘图的话,会有图像框出来,但是一闪而过,不会显示图像,此时要在绘图后加上之后图像就可以正常显示
labelme没有draw文件了,实现标注是调用imgviz库的label文件,所以改一下label文件的相应代码就可以实现了。具体位置在conda虚拟环境位置下的envs/labelme/lib/python3.6/site-pavkages/imgviz/label.py中,将r = np.bitwise_or(r, (bitget(id, 0) << 7 - j))g = np.
大模型训练分阶段流程概述 大模型训练遵循严格顺序:预训练→指令微调→奖励建模→强化学习→优化改进。 预训练:通过海量文本学习语言规律,使用无监督数据(如JSON/TXT格式文本),训练工具有Megatron-LM、DeepSpeed等。 指令微调(SFT):让模型学会遵循人类指令,使用指令-回答对数据(JSON格式),常见工具包括LLaMA-Factory、Hugging Face PEFT等。
1.收集数据集,清理数据集2.手动标注部分数据集3.将标注好的数据集用自己的模型训练4.将未标注数据用模型进行预测,输出预测文件5.将预测的数据重新导入标注工具,进行人工调整
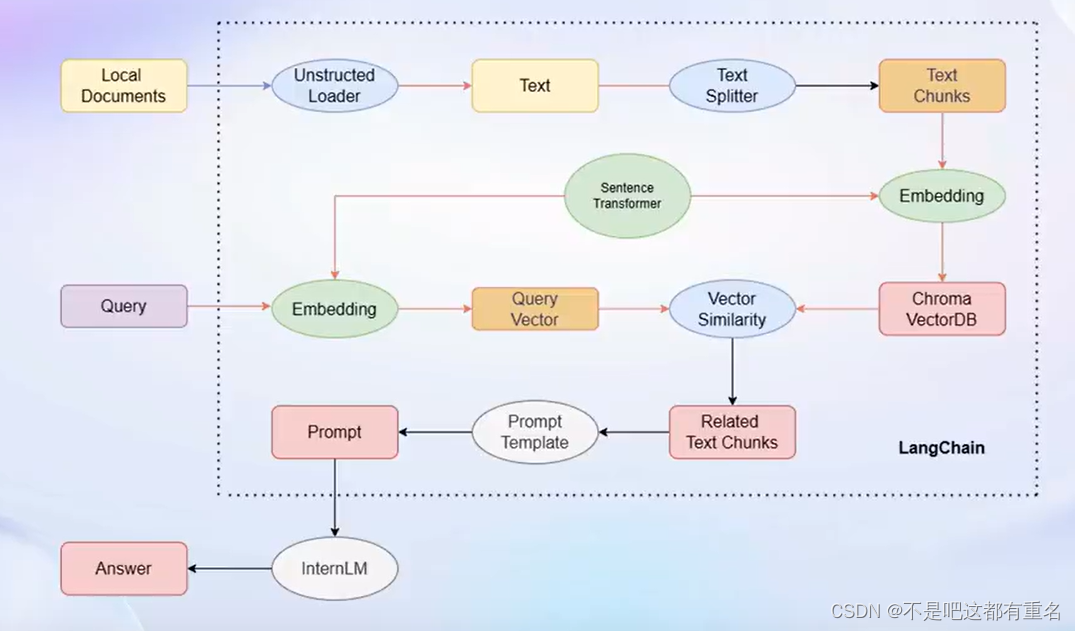
llm.predict("你是谁")构建检索问答链,还需要构建一个 Prompt Template,该 Template 其实基于一个带变量的字符串,在检索之后,LangChain 会将检索到的相关文档片段填入到 Template 的变量中,从而实现带知识的 Prompt 构建。from langchain . prompts import PromptTemplate # 我们所构造的 Prom
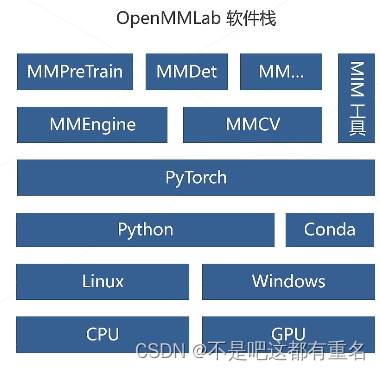
MMPretrain是一个全新升级(MMPretrain originates from MMClassification and MMSelfSup )的预训练开源算法框架,旨在提供各种强大的预训练主干网络,并支持了不同的预训练策略。主要功能:(1):包括主干模型、自监督学习算法、多模态学习算法(2):COCO、ImageNet等常见数据集(3):优化器与学习率策略、数据增强策略(4)
大模型训练分阶段流程概述 大模型训练遵循严格顺序:预训练→指令微调→奖励建模→强化学习→优化改进。 预训练:通过海量文本学习语言规律,使用无监督数据(如JSON/TXT格式文本),训练工具有Megatron-LM、DeepSpeed等。 指令微调(SFT):让模型学会遵循人类指令,使用指令-回答对数据(JSON格式),常见工具包括LLaMA-Factory、Hugging Face PEFT等。
本文介绍了如何在Ollama中运行本地微调的GGUF格式模型。主要内容包括:1)准备GGUF模型文件;2)创建Modelfile定义模型路径、系统角色和推理参数;3)使用ollama create命令注册自定义模型;4)通过ollama run运行模型。文档还提供了调优建议和模型管理方法,帮助用户灵活使用自定义模型功能。整个过程简单易行,只需准备模型文件和Modelfile即可在Ollama中运行
本文介绍了如何在Ollama中运行本地微调的GGUF格式模型。主要内容包括:1)准备GGUF模型文件;2)创建Modelfile定义模型路径、系统角色和推理参数;3)使用ollama create命令注册自定义模型;4)通过ollama run运行模型。文档还提供了调优建议和模型管理方法,帮助用户灵活使用自定义模型功能。整个过程简单易行,只需准备模型文件和Modelfile即可在Ollama中运行