- @qq_41697157
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1. tensor是深度学习的基础,需熟练掌握其创建、存储、操作和设备迁移;2. 内存核算需关注浮点类型(float32/bf16/fp8)的取舍,计算量核算核心是矩阵乘法的FLOPs;3. Einops简化tensor维度操作,提升代码可读性;4. MFU是衡量硬件利用率的核心指标,优化MFU是提升训练效率的关键。
斯坦福从头构建大模型课程cs336第一讲内容,讲解大模型发展历史、课程作业安排、tokenization
当你看到这样一个新闻:“某实验室/公司喜报:使用某开源基座模型Q,经过后训练得到模型Q',Q'在数学编程领域的得分超过Q。” 请思考,Q'真的超过了Q吗?学习本节课,你将了解什么是后训练,为什么后训练会导致模型灾难性遗忘,如何避免模型遗忘知识。

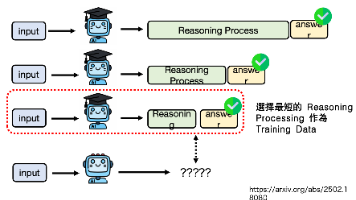
上一讲我们提到,推理模型的挑战在于:冗长的推理过程造成模型低效和高的推理成本。本文会按照“问题 → 解法 → 落地” 三个步骤记录,不让模型想太多的方法。
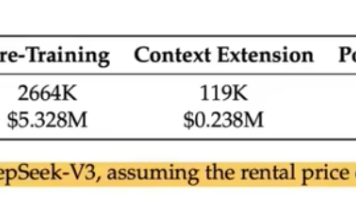
DeepSeek 2024年1月至2025年1月,技术演进摘要。基座模型(DeepSeek LLM、DeepSeek MoE、DeepSeek-V2、DeepSeek-V3);推理模型(DeepSeek-Coder、DeepSeek-Coder-V2、DeepSeek-Math-Shepherd、DeepSeek-Math、DeepSeek-Prover、DeepSeek-Prover-V1.5、
本文探讨了大型语言模型在多个关键方面的表现特性:1. 模板格式对输出质量的影响分析显示,使用适当的对话模板能显著提升回答的相关性。2. 多轮对话测试,证实模型能有效记忆上下文。3. 通过tokenization分析展示了文本如何被拆分为子词单元。4. 不同采样策略对比实验表明,不同采样方式对模型输出的多样性有影响。5. 词嵌入可视化证实语义相近的词在向量空间中距离更近。6. 注意力机制分析揭示

AIAgent是指能自主完成人类设定目标的智能体,其核心能力包括:1)基于记忆的经验调整,通过读写模块实现记忆管理;2)工具使用能力,可调用搜索引擎、编程接口等多类工具;3)动态计划能力,能根据环境变化调整行动计划。当前AIAgent已从专用系统(如AlphaGo)发展为通用型智能体,支持语音交互等更自然的交互方式,且无需专门训练模型即可运作。未来发展趋势包括更复杂的记忆机制、工具自主选择及动态计

当你看到这样一个新闻:“某实验室/公司喜报:使用某开源基座模型Q,经过后训练得到模型Q',Q'在数学编程领域的得分超过Q。” 请思考,Q'真的超过了Q吗?学习本节课,你将了解什么是后训练,为什么后训练会导致模型灾难性遗忘,如何避免模型遗忘知识。
一句话总结——“所有架构都为了解决上一代模型的致命缺陷而生:CNN 解决参数爆炸,ResNet 解决梯度消失,Transformer 解决 RNN 无法并行,而 Mamba 则试图一次解决 Transformer 的 O(N²) 与 RNN 的记忆瓶颈。”

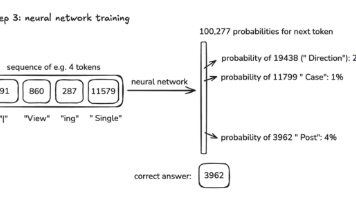
本文总结了安德鲁·卡帕西关于大语言模型的核心观点。大模型训练分为三个阶段:预训练(学习语料)、监督微调(学习对话)和强化学习(优化输出)。预训练包括数据处理、token化和神经网络参数调整;监督微调通过对话数据集教会模型应答;强化学习则让模型自主优化答案质量。文章还探讨了模型特性(如幻觉、记忆方式)和发展方向(多模态、任务代理等),并提供了相关资源链接。这种分阶段训练方法使大模型能逐步掌握从知识积