




- @qq_41518277
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
title: 机器学习(V)–无监督学习(二)流形学习date:katex: truecategories:Artificial IntelligenceMachine Learningtags:机器学习cover: /img/ML-unsupervised-learning.pngtop_img: /img/artificial-intelligence.jpgabbrlink: 26cd5aa
根据训练样本中是否包含标签信息,机器学习可以分为监督学习和无监督学习。聚类算法是典型的无监督学习,目的是想将那些相似的样本尽可能聚在一起,不相似的样本尽可能分开。

说明:本手册所列包来自Awesome-Python ,结合GitHub 和官方文档,参考 SeanCheney 大神在简书上翻译的《利用Python进行数据分析·第2版》,整理所得。pandas兼具NumPy高性能的数组计算功能,提供数据操作、准备、清洗等数据分析最重要的技能。...
xgboost 在 xgb.train中通过参数obj和custom_metric来自定损失函数和评估函数。自定义损失函数接受predt和dtrain作为输入,返回损失函数的一阶(grad)和二阶(hess)导数。'''自定义损失函数后,模型的输出不在是 [0,1] 概率输出,而是 sigmoid 函数之前的输入值。因此,需要写出对应的评估函数。评估函数也接受predt和dtrain作为输入,返回
LightGBM的参数比SynapseML公开的要多得多,若要添加额外的参数,请使用passThroughArgs字符串参数配置。您可以混合passThroughArgs和显式args,SynapseML合并它们以创建一个要发送到LightGBM的参数字符串。如果您在两个地方都设置参数,则以passThroughArgs为优先。
数学物理方法球函数勒让德方程的解勒让德函数连带勒让德函数球谐函数柱函数贝塞尔方程的解贝塞尔函数球贝塞尔方程偏微分方程(Partial Differential EquationI)偏微分方程(Partial Differential EquationII)偏微分方程(Partial Differential EquationIII)球函数勒让德方程的解求解勒让德方程(Legendre equati
PSI(Population Stability Index)指标反映了实际分布(actual)与预期分布(expected)的差异。在建模中,我们常用来筛选特征变量、评估模型稳定性。其中,在建模时通常以训练样本(In the Sample, INS)作为预期分布,而验证样本在各分数段的分布通常作为实际分布。超参数调优算法主要有网格搜索(Grid Search),随机搜索(Randomized S
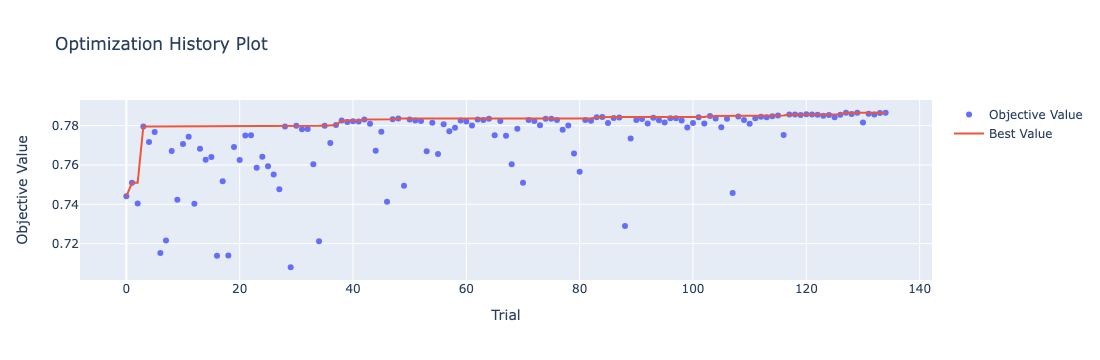
我们使用dict()说明用于分类参数,返回options 中的元素返回 (probability, option) 元素对返回区间 [low, upper) 内的随机整数均匀返回 low, high 之间的浮点数均匀返回 low, high 之间的浮点数,适用于离散值均匀返回 low, high 之间均的整数,适用于离散值对数均匀返回 elow,ehigh之间浮点数对数均匀返回elow, ehig
数学符号希腊字母LaTexKaTex===is equal to=≠\ne̸=is not equal to\ne≈\approx≈is approximately equal to\approx+++plus+−-−minus-±;∓\pm; \mp±;∓plus-minus; minus-plus\pm; \mp...
Regression一般线性回归TheoryModel ClassesResults ClassesExamples广义线性回归TheoryModel ClassesResults ClassesExamples广义估算方程线性混合模型离散因变量回归ExamplesPython手册(Machine Learning)–statsmodels(Quickstart)Python手册(Machi...