




- @qq_36894974
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
7 月 18 日,OpenClaw 作者 Peter Steinberger 在 X 上问了一句:大家还在聊 Loop,还是已经转向 Graph 了?两天后,Codez 写了一篇很长的教程,给出一条从零开始学习 Graph Engineering 的 14 步路线。先补一句 Loop 是啥:Loop 是让单个 Agent 反复自我检查、自我修正,直到结果达标为止的机制——写完一遍、检查一遍,不行就
在 CursorBench 3.2 上,Opus 5 开到 max effort 后,距离 Fable 5 的峰值不到 0.5%,每个任务的成本只有一半。而且 Anthropic 在最新的提示词文档里专门说了,以前给旧模型加的最后再验证一次,或者找个 SubAgent 复查之类的提示,可以直接删掉。它用略高于 Fable 5 三分之一的成本,超过了 Fable 5 的最好成绩。现在模型跑长时任务已
前两天我看到有人把 Claude Design 的系统提示词整理出来了。仓库叫。我花时间看了一遍。虽然 A 社太 xxx ,但是不妨碍我们研究它的产品,主打就是一个把它给蒸了。我看完之后,有一个深深的感触,就 A 社这帮 shit ,看来也被 AI 味折磨得够呛啊,基本上大家有 AI 味儿的观感全写进去了。连最近特别流行的米白底 + 衬线大标题 + 陶土色都写进了违禁清单,说这玩意儿就是去年的紫色
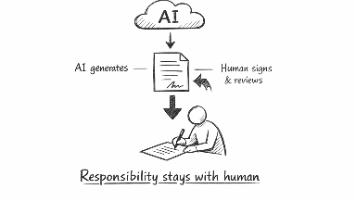
Linux 可以接受 AI 参与写出来的内容,但不会接受没有责任人的内容。这句话听起来不激进,却很有分量。它意味着一个成熟社区终于不再纠结“AI 到底该不该来”,而是开始认真设计“AI 来了之后,责任怎么分、风险怎么控、质量怎么守”。这比单纯的支持或反对都更重要。所以,AI 进入开源社区,已经不是趋势判断题了,而是治理能力题。真正的分水岭,不是谁先用上 AI,而是谁先建立起一套人能负责、流程能追溯
这两天我注意到一个 Github,刚看到的时候,还是有点搞笑的。看到这个 readme ,你第一反应是不是会想到又是哪个大聪明在恶搞。或者觉得这又是一个什么恶趣味的 Github。其实不是,这是一个正经的能帮助大家减少 Token 消耗的 Github。它的介绍是这么说的让你的 Agent 一样像个成熟的高级开发人员一样,最好的代码就是你不写代码。你现在看到这个介绍,会不会想起来你接触的高级开发,
我之前没有好好理解 AI 数据库的概念,我以为就是 AI 数据库外加一个检索插件,如果你像我这么理解,那恭喜你,跟我一样跑偏了。在一个由 AI 驱动的世界里,数据应当如何被组织、被理解、被调用,这一点尤为关键。在传统的数据库组织形式中,这个问题好回答,当然是碳基生命 — 人。而在 AI 时代,我觉得应该让 Agent 来回答这个问题。如果要由 Agent 来回答这个问题,我觉得得从两条线上来讲。第
在 ExploitBench 这份测评榜单上,GPT-5.6 Sol 用了大约 1/3 的 Token,就接近了 Mythos Preview 的水平。在 ExploitGym 上,Sol、Terra、Luna 随着推理的增强,也都展现出了明显的网络安全能力提升。OpenAI 的说法是,GPT-5.6 Sol 比 GPT-5.5 更强,而且用的 Token 更少。过了两周了,估计大家都忘了 GPT
但是,在大家都很关注的 SWE-Bench 领域中, Fable 5 显著胜出 GPT-5.6 ,Fable 5 取得了 80% 的成绩,而 GPT-5.6 Sol 为 64.6%。我自己实测了几轮,我没有用上 Sol ,我测试的是 Terraultra 模式,他给我的感觉是,不如 GPT 5.5 ,输出速度很慢,而且我刚开始用,就出现了两轮问题。不过不知道为何,之前说的 Plus 是可以使用 S
这套机制最膈应人的地方在于,它不是拦截你,它相当于一个精通社会工程学的人在角落里默默看着你在做什么,然后在合适的时间采取行动,你每次发现不对劲的时候,你的信息早就被扒的一干二净了。“除非我们与您另有特别约定,我们可随时通过通知您来终止本条款,并且若您违反本条款的任何规定,本条款将自动终止,无需另行通知。这意味着,A 社 在终止服务这件事上拥有极大的自由权,它可以随时终止,甚至在用户违反时无需任何通
我正在连载 Claude Code 系列体系文章,这是整个系列的第二篇。如果你觉得这个系列不错的话,欢迎追更,完全免费。Claude Code 是一个跑在终端里的 Agent runtime。它里面有 Query Loop,有 Tool System、Tasks、State、 Memory、Hooks。这些东西听起来已经够复杂了。那么问题来了。Claude Code 里面塞了这么多东西,为什么用户