




- @qq_33489819
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
AI时代的焦虑与节奏:在技术狂潮中保持平衡 这两年AI技术的快速发展让人陷入一种矛盾状态:兴奋与焦虑并存。一方面,新模型不断突破,工作流持续革新,带来"无所不能"的亢奋感;另一方面,FOMO(错失恐惧症)驱使人们停不下来地追逐每个新机会。文章指出,AI时代最易透支的不是能力,而是生活节奏——即时反馈让人沉迷于"再看一点、再试一个"的循环,看似高效实则失衡。

【模型评测指南:如何看懂各家发布的榜单成绩】 当前AI模型评测呈现明显的代际演进特征:第一代主打知识问答(MMLU、GPQA),第二代侧重图文理解(MMMU Pro),第三代转向实操能力(SWE-Bench、Terminal-Bench)。最新趋势聚焦工具调用(MCP Atlas)和Agent工作流(t2-bench)。建议用户根据需求选择关键指标:编程看SWE-Bench、终端操作看Termin

Zsh 配置文件设计遵循清晰的进程分层模型,针对不同场景加载不同文件:.zshenv(所有进程的最小环境)、.zprofile(登录会话初始化)和.zshrc(交互式终端优化)。理解这种分层机制能避免配置混乱——全局变量放.zshenv,PATH等会话级配置放.zprofile,交互功能放.zshrc。MacOS因默认加载全部文件容易混淆,但IDE执行命令时差异就会显现。核心原则是按进程类型而非个

本文介绍了三种实现结构化输出的方法,使大模型能输出程序可解析的JSON格式数据: Prompt指令法:直接在提示词中要求模型输出JSON,简单但不可靠,可能包含多余文本或格式不一致。 JSON Mode法:通过API参数强制输出纯JSON(无多余文本),但需要提示词中也明确要求JSON输出,适用于百炼平台等兼容OpenAI格式的环境。 JSON Schema法(未展开):可进一步约束输出结构,确保
本文介绍了如何为AI模型实现对话上下文管理。作者指出模型本身没有记忆功能,每次调用都是独立的推理过程。实现上下文记忆的关键是将历史对话记录存储在消息列表中,并在每次请求时发送完整的对话历史。 文章通过Java代码示例展示了最基本的实现方案——用List存储所有消息。但这种方法存在token数量限制的问题,可能导致API调用失败或成本过高。针对这一问题,作者提出了三种优化策略: 滑动窗口策略:只保留

摘要 本文介绍了大模型工具调用(Function Calling)的核心概念和发展历程。从2023年6月OpenAI首次引入functions参数,到11月升级为更通用的tools接口,支持多种工具类型扩展。文章通过"查天气"示例演示了完整流程:1)定义工具JSON Schema;2)模型返回调用决策;3)开发者执行实际函数;4)将结果返回模型生成最终响应。重点强调了模型仅负责

本文介绍了如何使用阿里云百炼平台进行大模型API调用的入门指南。文章建议开发者先理解底层API调用机制,而不是直接使用框架。通过Java代码示例展示了最简单的API调用方式,详细拆解了messages参数(包含system、user、assistant三种角色)、model选择(qwen-turbo/plus/max)、temperature和top_p(控制回复随机性)、max_tokens(限

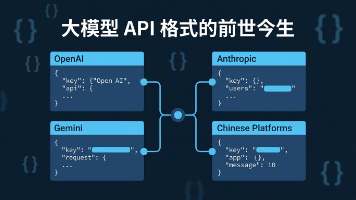
大模型API格式发展历程显示,主流厂商各自为政,导致接口规范混乱。OpenAI先后推出两套互不兼容的Chat Completions和Responses API,Anthropic采用独立system字段设计,Gemini则使用contents结构。国内平台多兼容OpenAI早期标准。核心差异体现在:system提示词位置(独立字段vs嵌入消息)、消息容器命名(messages/contents)
推荐几个优化提示词的提示词
