




- @qq_29707567
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
解决办法参考了网友的建议,拉docker的时候增加了参数--shm-size 8G,增大了内存,确实有效,感谢分享,特地记录下,以备后续查阅docker run--gpus all --name 0725test --shm-size 8G-v /mnt:/mnt -itnvidia/cuda:11.7.1-devel-ubuntu20.04-deepspeed /bin/bash参考链接:ERR
事件列表页:展示2_event表中的主要字段,并增加一列,判断对2个csv文件中的数据进行关联,判断2_event 表中的src_ip 是否为1_threat中的indicator。control+L 打开对话区域,描述系统的框架需求、实现方式、数据库要求、语言要求、功能页面需求等,之后即可以自动在本地生成代码,并提供部署运行、访问的方式。免费版使用次数有限制,尝试使用插件方式删除账户并重新创建后
shutdown -h now
一、vscode彻底删除。
2.1 确认系统架构uname -m2.2 根据架构下载对应的conda安装文件。

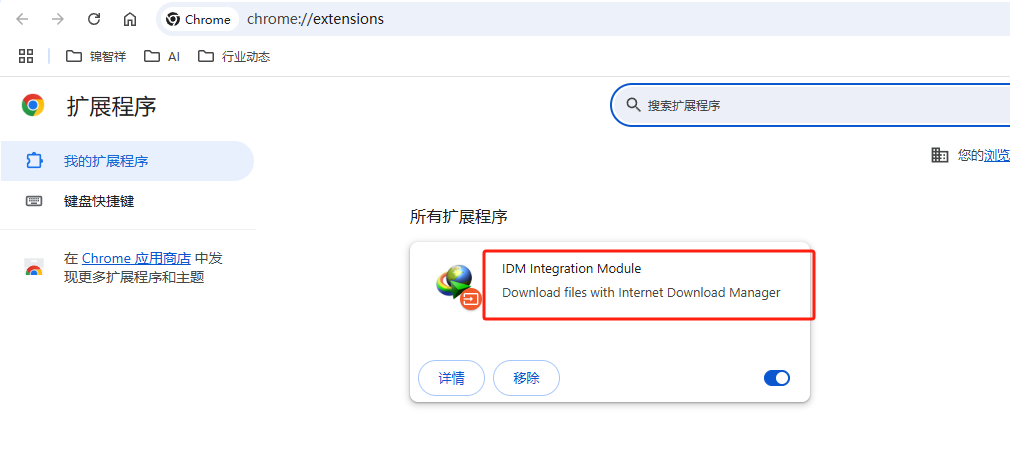
3、如果视频比较多的话,目前是手动一个个点击来下载的,f12中没有找到对应的mp4文件,目前这种方式靠手动,没有实现自动化。2、电脑上chrome浏览器打开抖音视频链接,浏览器弹框提醒下载,手动点击进行保存。1、chrome浏览器-扩展程序中开启idm插件。
21年组内会有一些关于数据仓库的新项目,了解一下相关测试方法https://www.sohu.com/a/253435102_672569
最近项目上遇到一些训练方面的测试,数据样本的不同,测试结果区别很大,准确率有时不高,网上查了下相关的帖子、做法,参考一下。参考一:转自(https://www.cnblogs.com/morwing/p/12144476.html)验证集 —— 是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进行初步评估。测试集 —— 用来评估模最终模型的泛化能力。但不能作为调参、选
opencl异构计算。
opencl异构计算。